Manacher’s Algorithm (Manacher 的唸法
/ˈmænəkər/),用是來尋找字串中的最長回文子字串 (Longest Palindromic Substring)的最優解法,時間複雜度可優化到了 O(n)。 在了解此演算法之前,可以先熟悉「 Dynamic Programming - 2D matrix 」和「 中心擴散法 (Expand Around Center) 」這些 O(n^2) 的解法,在解題途中有蠻多直得注意的技巧和知識點可以學習,由於算是是常考題,就花些時間了解一下吧。
蠻多 coding 語言在一般情況下是使用
32 bits的空間來儲存整數的,例如 Java 的 int,範圍是-2147483648 ~ 2147483647,大約正負21億。但是現實世界中,較小的數字往往比較常出現,大約幾十到幾十萬是最多最常出現的,如果只是要儲存或傳輸這樣的一個小數字,卻每次都需要用到 32 bits 的空間,其實有點浪費,這是有機會優化的 !Varint 和 Zigzag 演算法就是要處理這種問題,讓值小的數字,可以用較少的 byte 數量表示,而達到資料壓縮目的,著名的資料傳輸格式 Protobuf 也是通過 Varint 和 Zigzag ,來大幅減少了資料佔用的空間。
Reservoir sampling 是一個隨機演算法,其目的是在只遍歷一遍的情況下,從大數據 N 的資料流中,隨機選取出 k 個元素,且每筆資料選中的機率都要一樣。這個場景強調了幾件事:
- 集合 N 很大且不可知,所以不能一次存入記憶體
- 時間複雜度為
O(N)- 隨機選取 k 個數,每個數被選中的機率為
k/N本來面對這種問題,比較直接的想法是利用隨機數演算法,求 random(N) 得到隨機數,但是因資料流極大,無法一次都讀到記憶體內,這就表示不能像數組一樣根據 index 獲取元素;而且題目強調只能遍歷一遍
O(N),代表也不能再採用分塊方式儲存資料,之後再隨機遍歷。為了解決這個問題,可以使用 Reservoir sampling ,非常的巧妙。
Backtrack 是 DFS 的一種形式,基本寫法類似於 TOP DOWN DFS,處理方式就是所謂的窮舉法,將所有可能的結果都找出來;每一個結果都實際看看這樣。換個角度來說,其實這個過程就如同在樹上遍歷 (Tree Traversal) ,而普通的 DFS 是不需要回溯狀態的。 Backtrack 強調了狀態回溯。
Quick Sort ,如原本名字所示速度非常快,又稱分割交換排序法。在比較好情形下,時間複雜度為
O(nlogn),往往比 Merge Sort、 Heap sort 等排序算法更快,其基本思想也是分治法 (Divide and conquer)。 基於 Quick Sort 思想也衍生出了 Quick Selection,在排序序列的同時,選擇出序列中「第 K 小」或是「第 K 大」的元素,因為不需要把整個 array 的排序做完,故其平均時間複雜度為O(n)。
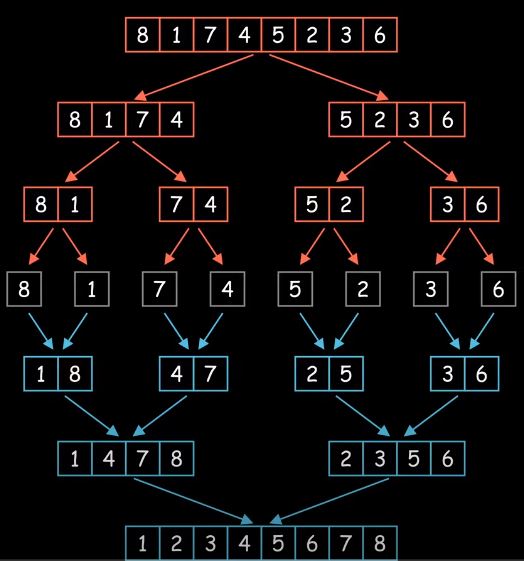
歸併排序 (Merge Sort) 算是比較優秀的排序算法,因為時間複雜度是
O(N log N);而選擇排序、冒泡排序、和插入排序時間複雜度則是O(N^2)。 Merge Sort 的基本思想是分治法 (Divide and conquer),是將原問題分解為規模較小的子問題,然後逐一解決這些子問題之後,合併這些子問題的答案,並建立原問題的答案。