
Cloud Functions 是一個無伺服器的雲端執行環境 (serverless execution environment),會把寫出來的 code 完全託管給 GCP 並且無需配置任何 Infra 也不用管理任何 Servers 就可以執行了,對於程式設計師來說只需要專注在自己的程式邏輯即可,基本完全省去管理硬體的煩惱,為最標準的 FaaS 類型服務。對應其他的雲端服務是 :
- Amazon Web Services (AWS) : AWS Lamda
- Microsoft Azure : Azure Functions
Cloud Functions 可以用 Java、Python、Node.js、Go 等常用 coding language 來撰寫,適用於部署單一化用途的程式,或用於連接擴展其他的 GCP 雲端服務,以 Events and triggers 為其核心設計思想。
Cloud NAT 全稱是 Cloud Network Address Translation,是 Google Cloud 代管的 IP 轉譯服務,可在不公開 IP 位址的情況下,讓 GCP VM 或 GKE 內的 Pod 可以高效的連接上「外部網路 Internet」,而外部資源無法直接存取 Cloud NAT gateway 後方的資源,維持獨立性與安全性。對應其他的雲端服務是 :
- Amazon Web Services (AWS) : NAT gateways
- Microsoft Azure : Azure NAT Gateway
Cloud NAT 是以 Software-defined Networking 服務,中間不存在 proxy instance ,故性能方面比傳統 NAT 好上不少。除了 VM、GKE 之外,也可使用在 Cloud Run、Cloud Functions、App Engine 等服務。
Cloud DNS 是 Google 提供的代管式的全球 Domain Name System(網域名稱系統服務),為一個分布式的分層資料庫(hierarchical distributed database) 用於存儲 IP addresses 和 Domain Name 的對應關係,還可以建立 DNS Zone 並在其下管理和創建 Record 。對應其他的雲端服務是 :
- Amazon Web Services (AWS) : Amazon Route 53
- Microsoft Azure : Azure DNS
Cloud DNS 是提供代管功能而不是註冊,而代管的好處是有一個「共同管理維護」的介面 ; 還能「基於地理位置」將流量轉到最接近的服務器從而提高性能與速度 ; 結合「 GCP 雲端安全服務」保護應用程式免於如 DDoS 攻擊。 最後比較特別的是 Google 的 Cloud DNS 服務號稱是 100% SLA 服務保證絕對不會中斷, Google 對其 DNS 服務設計非常的有信心。
CDN 全名為 Content Delivery Network,是一種透過分散在不同地區的 server,用離使用者最近的伺服器來傳送快取內容。而 Cloud CDN,就是借助 Google 分佈在全球各地的網路節點,將內容以快取(Cache)形式預先儲存,以達到最快速的內容交付。對應其他的雲端服務是 :
- Amazon Web Services (AWS) : Amazon CloudFront
- Microsoft Azure : Azure CDN
Cloud CDN 會需要與 GCP-Load-Balancer 搭配使用,故建議可以先熟習 GCP 負載平衡器的基本用法和觀念。
Cloud Load Balancing 是 GCP 透過平均分發流量到多個 server ,以防止單一伺服器的過載從而減少系統故障的風險的產品,對應其他的雲端服務是 :
- Amazon Web Services (AWS) : Elastic Load Balancing
- Microsoft Azure : Azure Load Balancer
因為只需透過配置單個對外 IP 地址和憑證,就可讓負載平衡器的內部的管理的所有 VM 被外網存取,故從購買 External IP 的角度來說 Load Balancing 也可算是一種降低維運成本的方式。
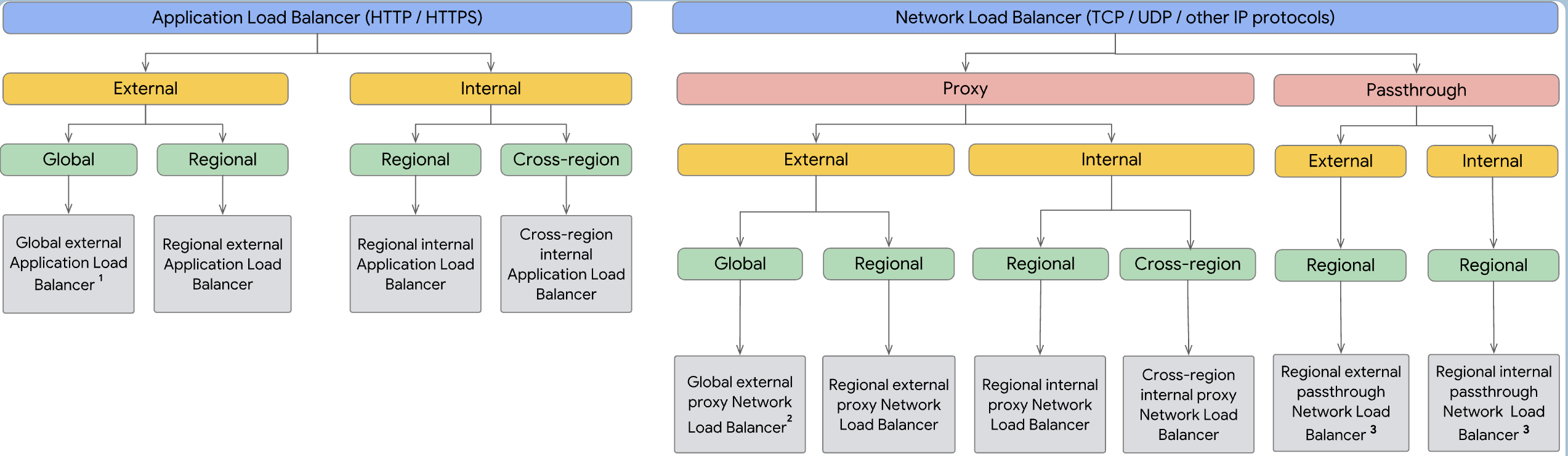
目前從 GCP console 上由流量類型劃分成了「 HTTP(S) 」和 「 TCP/UDP 」兩大類 Load Balancing ,然後在依照細部應用場景還有分成 「Global/Regional」 和 「Internal/External」 等等各種組合,總體設定蠻精細的,可以對應不同的場合需求。
Cloud 是最能展現自動伸縮擴展服務好處的平台,而 GCP 的 Autoscaling Groups of Instances 代表產品是 Managed Instance Groups (簡稱 MIGs) ,雖然名稱有一點點不太直覺。 GCP 會根據自訂義的 Autoscaling Policy 來自動添加或刪除 VMs ,這些自動縮放而產生的 VMs 會有一個群組來管體,就是 MIG。對應其他的雲端服務是 :
- Amazon Web Services (AWS) : Auto Scaling groups
- Microsoft Azure : Virtual Machine Scale Set
MIGs 的 Autoscaling Policy 再詳細說一些,是能夠基於 Application 的 CPU/Memory 使用率、網路流量等等設定,自動增加或減少 VM,可根據業務需求或突發流量的場景,靈活調整資源數量從而保證高性能和成本彈性。