
Manacher’s Algorithm
Manacher’s Algorithm (Manacher 的唸法
/ˈmænəkər/),用是來尋找字串中的最長回文子字串 (Longest Palindromic Substring)的最優解法,時間複雜度可優化到了 O(n)。 在了解此演算法之前,可以先熟悉「 Dynamic Programming - 2D matrix 」和「 中心擴散法 (Expand Around Center) 」這些 O(n^2) 的解法,在解題途中有蠻多直得注意的技巧和知識點可以學習,由於算是是常考題,就花些時間了解一下吧。
預備知識點
字串前處理
回憶一下之前在解 leetcode 5. 的時候,有使用了中心擴散法 (Expand Around Center)。考慮對稱軸的形式,此時會需要分成「偶數長度」和「奇數長度」的 Palindrome ,這些全部都要做判斷才行。比如 :
- 「 baab 」此時對稱軸是介於兩個字元「a」中間的
- 「 aba 」 此時對稱軸是「a」這個單字
所以之後更下方解法中,有使用一個一種巧妙的辦法,就是在字串頭尾和其中間,都插入特殊符,比如 _ 或者 # 等等(下面圖片用 _ 表示)。如此一來原本字串經過前處理,就一律轉成 「奇數長度」的字串了,這件事情一定成立嗎?再來思考,原本是 Palindrome 的字串,經過「這樣的處理之後」仍然還會是 Palindrome 嗎?
以上兩個問題的回答都是成立的,也就是:
- 任何字串,經過以上定義的前處理後,都會變成 「奇數長度」的字串
- Palindrome 經過以上定義的前處理後,還是會維持 Palindrome
證明
原本字串經過「在字串頭尾和其中間,都插入特殊符」處理之後,一定變成「奇數長度」的字串
假設原字串有 n 個字元,在頭尾,和所有字元中間都插入 _,由於
- 字元和字元之間的「間隔」會有
n - 1個 - 再加上最前端、最尾端
2個
故處理後字串中特殊符號的數量就是: (n - 1) + 2 = n + 1。那又因為 「處理後字串字元的數量」 =「原本字元的數量」+「特殊符號的數量」,故得到新字串的總長度: n + (n+1) = 2n + 1,由於 n 是整數,故 2n + 1,結果必然是一個奇數,Q.E.D.
原 Palindrome (P) 經過在頭尾與字元中間插入相同特殊符號處理後,得到的新字串 New Str(NS),其也必然是 Palindrome
設 P 其長度為 n,根據回文的定義得到: P[i] = P[n - 1 - i], for 0 <= i < n ,代表從左邊數來第 i 個字元等於從右邊數來第 i 個字元。假設使用的特殊符號為 _,經過處理後的新字串為 NS 長度承前證明知道為 2n + 1,這時 NS 的任意索引 i 在 0 <= i < 2n+1 :
- 當
i是偶數時(0, 2, 4, …, 2n),該位置必定是_ - 當
i是奇數時(1, 3, 5, …, 2n+1):該位置存放的是原字串的字元,其表示關係為:NS[i] = P[(i-1)/2]
現在目標是證明: NS[i] = NS[(2n+1) - 1 - i], for 0 <= i < 2n+1 ,稍微修正一下式子:
NS[i] = NS[2n - i], for 0 <= i < 2n+1
分兩種情況來討論:
如果
i是偶數,那麼2n - i(偶數減偶數)也必然是偶數,根據映射規則,只要索引是偶數,NS該位置的值就一定是_,所以NS[i] = NS[ 2n- i]在i是偶數恆成立如果
i是奇數,2n - i(偶數減奇數)必定是奇數,那:- 左側
NS[i]直接從上面分析得到P[(i-1)/2] - 右側
NS[2n - i], 令j=2n-i則 :
NS[2n - i] = NS[j] = P[(j-1)/2] = P[(2n-i-1)/2] = P[n - 1 - (i-1)/2]若令
k = (i-1)/2,則會得到:P[k]和P[n - 1 - k]。由於 P 就是 Palindrome, 所以P[k] = P[n - 1 - k]。所以NS[i] = NS[ 2n- i]在i是奇數也恆成立- 左側
承上分析,新字串 NS 必然也是一個 Palindrome, Q.E.D.
迴文字串半徑 ( Palindromic radius )
例如以下圖說 _a_b_a_b_a_,以最中間的 a 當中心,往右數有 _, b, _, a, _ 有 5 個,且往左數也對稱一樣。所以 _a_b_a_b_a_, radius 為 5。
計算半徑長度的時候,略過中心
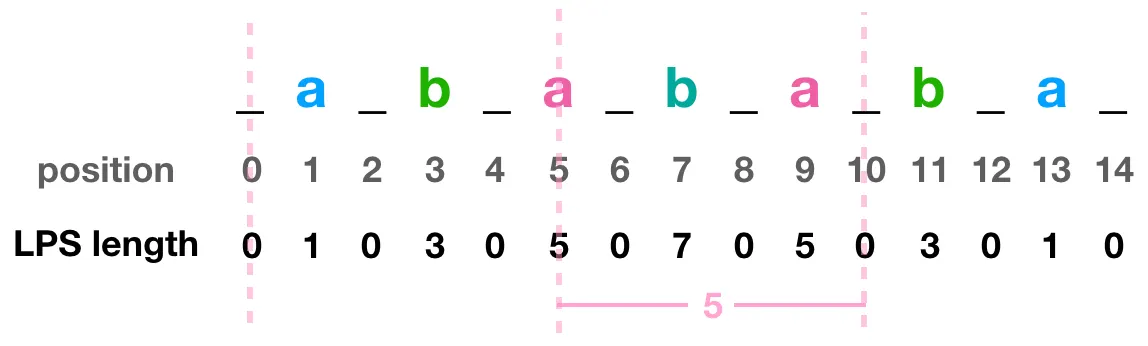
按照此方式,可以把所有 position index 和 radius 都寫出來。如果是偶數長度的也沒關係,一樣可以計算,下圖也舉個範例:
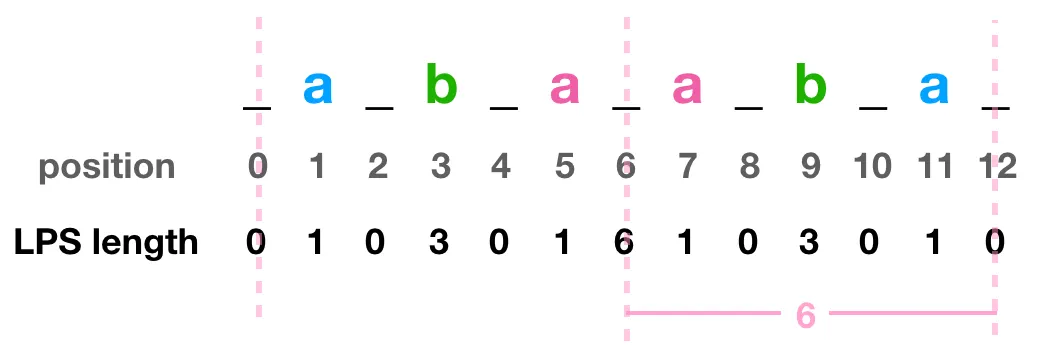
接著還是以 _a_b_a_b_a_ 來當範例,再仔細觀察會發現 :
_a_b_a_b_a_,已最中間的a當中心,半徑是5- 拿掉多加的符號後會變成
ababa,其長度是5 - 這兩個一樣,都為
5這個值。
再舉例其他 :
_a_b_b_a_,已中間的-當中心,半徑是4(b,_,a,_有 4 個)- 原本的字串中(拿掉多加的符號),已上面同樣的空心位置當中心,
abba長度是4 - 這兩個一樣,都為
4這個值
上面的事情是巧合嗎?
證明
有一個 Palindrome ,其長度和「經過字串處理過的 Palindromic radius 」,兩者是相等的
假設原本 Palindrome 的長度設為 L ,經過「字串前處理」後 ; 設新字串中的總字元數為 M。承前面的證明知道: M = 2L + 1, L 為原本字串長度 。
對於新字串,承前面的證明知道一定奇數長度,且新字串也一定為 Palindrome,故裡面一定存在一個中心點,有半徑 R(不包含中心點本身),因此新字串總長度公式為:M = 2R + 1。
故 R = L, Q.E.D.
有了中心位置和半徑, 原本 Palindrome 是什麼也可以簡單推斷出來
了解了前面的預備知識點,我們可以知道: 如果能夠快速地找出所有子字串的最大 Palindromic radius ,並再找出其中最大的 radius,其實就等價於找到 Longest Palindromic Substring! 要如何更快速地得到呢?
Manacher’s Algorithm
Manacher’s Algorithm 更進一步利用了對稱性質,例如說:s 是個以 3 為中心,長度為 7 的 Palindrome ,若已知 s[0:3] 是 Palindrome,那 s[4:7] 也必定是 Palindrome。實際舉例:
s = 'abacaba's[0:3] = 'aba'- 則
s[4:7]必定是'aba'且也是 Palindrome。
Manacher’s Algorithm 步驟中,還可以再做「更進一步」的字串前處理。也就是除了一般字串前處理之外,還會再把頭尾接上一個「不同」的符號例如 $ 和 ^。這是為了後續的程式設計方便,避免 index out of range。因為在程式運算過程中,也使用 expand around center 的做法,是比對到「相同」的字元還會繼續往外比對,因此故意在頭尾加上不同的且 s 中沒有出現的字元,便可以確保比對到頭、尾時停止比對,不需要額外做邊界判定。
現在我們假設原始自串 s 經過上面的「字串處理」之後,變成新的字串 t 。接著定義 z(i) ,表示「t 字串以 i 為中心時的 Palindromic radius」,先用下圖範例說明:

由左至右逐一計算 z,並且額外追蹤兩個數值:
- 目前為止「抵達最右邊」的回文字,記錄其字尾的 index,設為
r - 目前為止 「抵達最右邊」的回文字的中心位置的 index,設為
c
例如說目前計算到 i=5,準備計算i=6,此時
- 抵達最右邊的回文字串為
#b#a#b# r = 7c = 4
照著中心擴展法比對,計算 i=6 時候,要比較是否 t[5]== t[7],但其實這步驟並不需要! 因為 t[7] 包含在「抵達最右邊的回文字串」範圍內(即上圖黃底範圍)。
因為 t[5~7]和 t[1~3] 是互相對稱的,所以要檢查 i=6 ,代表可以檢查對稱的位置 i=2,而該位置已經計算過了: z(2)=1 ,這個的隱含著是 z(6)>=1,以 i=6 為中心,「至少」有一個向外延展 1 的回文字。所以不用比較「是否 t[5] == t[7]」了,可直接從 「是否 t[4] == t[8] 」開始比較。
上面只是其中一種情形而已,更詳細說明如下:
情況討論
假設現在 loop 到了要計算 current_right 位置的回文半徑,當然這個位置左邊以前的回文半徑值已經都知道了,所以也可以知道 :
- current right 的左邊,一定有個中心點,故可以得到這個 center 的 index 位置
- 同時可得到回文半徑的覆蓋範圍是從 center_left 到 center_right,而這個 center 對應到的 center_right 是目前最大(最右邊)的 index 也可以知道
那觀察 current_right 對稱點左面出現的這個小回文字串 current_left,這個字串有以下幾種情況:
Case1. 如果 current_left 的左邊界,在「大回文字串的**左邊界之內**」,那麼 current_right 也不會觸碰到大回文字串的右邊界
最簡單舉例 dacaxacad這個字串,左側的aca 沒有超過這個大回文字串的左邊界,那麼右面對稱出的 aca 也不會超過右邊界。在這種情況下,右面這個小回文字串的長度與對稱的小回文字串的長度相等,絕對不會超過這個大回文字串。
詳細講解可以在參考下圖另一個範例講解:
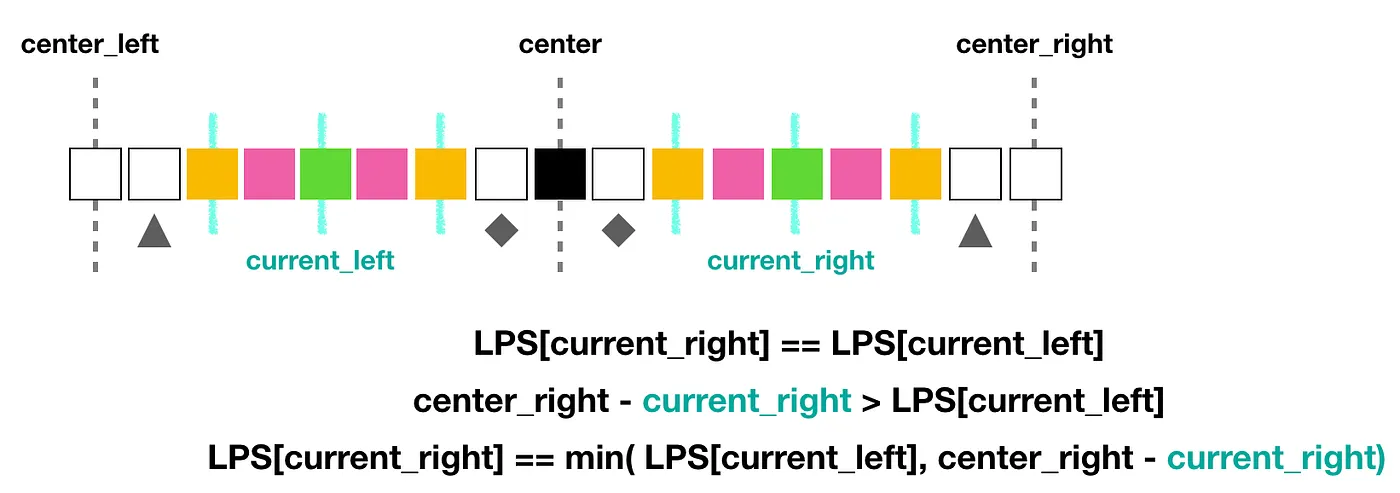
如圖所示,若 current_left 的範圍是(左邊的三條淺青色的直線),被「涵蓋在 center_left 到 center 裡面」,且也沒碰到最左邊界。那這時候一定代表 current_left 範圍外面那兩格一定不相等(上圖例使用左邊灰色三角形跟菱形代表)。由於 current_left 可用 center 的鏡像到完全對稱 current_right ,故可以直接得到:
current_right的回文半徑等於current_left的回文半徑
Case2. 如果 current_left 的左邊界,「**超過了**大回文字串的左邊界」,那這個 current_right 會正好觸碰到大回文字串的右邊界,但是不會超出。
比如觀察這個字串 dcbabcdxdcbabce,左側的小回文字串 dcbabcd 的邊界超出了用以 x 為中心的大回文字串的左邊界。 對稱過來的右側的小回文字串 cbabc 的邊界會剛好卡在大回文字串的右邊界。
因為「大回文字串右邊界之外的下一個字母」(此處是「e」),絕對不會是最左邊界的那個字母,所以右邊的小回文字串延申到邊界之後也無法繼續延申下去了。也就是說,在這種情況下,右面這個小回文字串的右邊界與大回文字串的右邊界相同,那麼這個小回文字串的長度也絕對不會超過這個大回文字串。
詳細講解也參考下圖另一個範例講解:
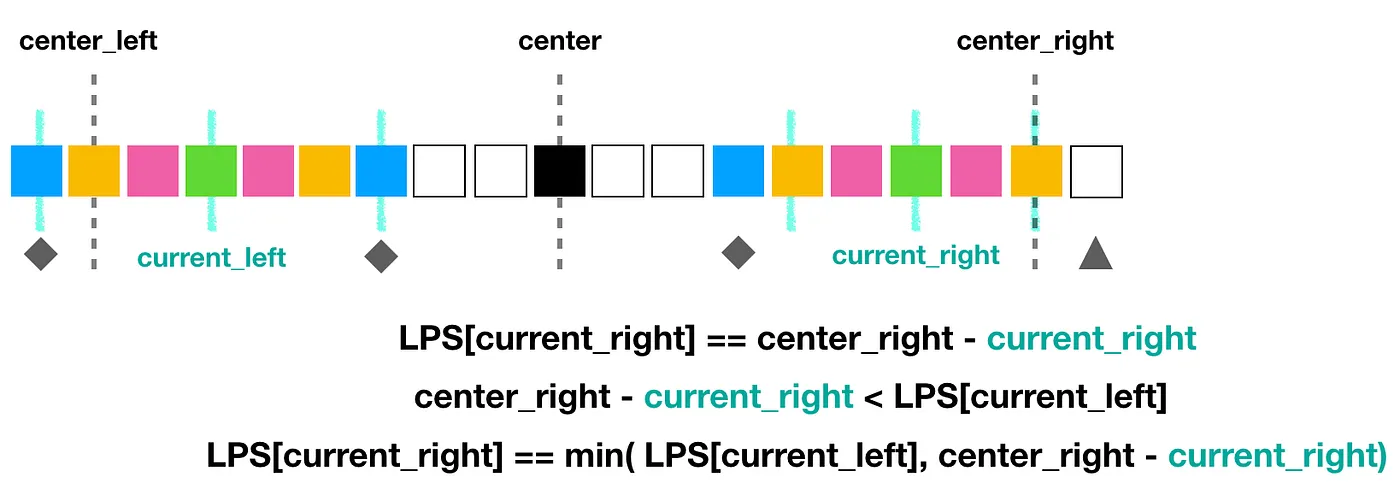
current_left上圖中兩格藍色位置必定相等- 根據 current_left 右邊藍色,再經過
center可對稱到更右邊的藍色 - 但是在
center_right的再右邊一格灰色三角位置,這個值一定不會等於藍色位置的值,否則 center_right 跟 center_left 就會往外擴張
所以可以得到
current_right的回文半徑 =center_right位置 -current_right位置
Case3. 如果 current_left 的左邊界,「**正好卡在**大回文字串的左邊界上」,那麼 current_right 有可能會繼續延伸下去,超過大回文字串的右邊界。
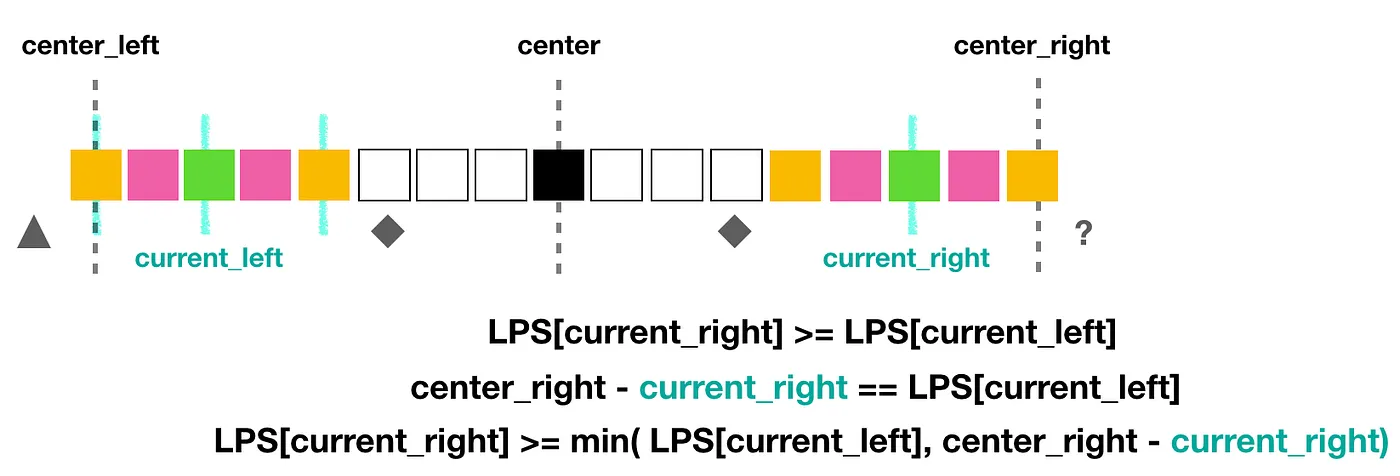
如圖片範例可以確定最左邊灰色三角形位置的值,一定不會等於菱形位置的值,但以 center 為中心的對稱範圍,我們不能肯定 center_right 再右邊一個的問號位置是什麼值,除非 center_right 已經是字串的最後一個字。
也就是這個情況, current_right 的長度才有可能會超過目前的大回文字串,而其他兩種情況的話,我們可以跳過不去計算。所以 Manacher 演算法在先找到一個長回文字串之後,可以選擇性的跳過很多字母,極大了提升了演算法的效率。
整理
承上觀念說明後,還可以再更精簡演算法:
- 使用
s = '$#' + '#'.join(s) + '#@',來處理字串 - 從
i=1開始逐次往右計算,並且記錄抵達最右的index r;抵達最右的回文字串的中心 index c - 做一個 dp 動態規劃矩陣來記錄「index c 的最大回文半徑」
- 承 case1 和 case2 ,可以知道:
current_right 的回文半徑 = min( current_left 的回文半徑, (center_right 位置- current_right 位置), ) - 不用實際上去分情況討論,無論哪種情況都嘗試向外繼續探測回文半徑能否延申(這也是字串處理還要加上
$和^的原因 - 「最右邊界最大 (right_index)」的中心,不一定是「長度最長」的回文,所以要另外維護:
- best_center
- best_len
class Solution:
def longestPalindrome(self, s: str) -> str:
if len(s) == 1:
return s
s = '$#' + '#'.join(s) + '#^'
n = len(s)
right_index = 0
right_central_index = 0
dp = [0] * n
best_center = 0
best_len = 0
for i in range(1, n-1):
if i < right_index:
dp[i] = min(
(right_index - i),
dp[2*right_central_index - i]
)
while s[i+(dp[i]+1)] == s[i-(dp[i]+1)]:
dp[i] +=1
if dp[i] + i > right_index:
right_index = dp[i] + i
right_central_index = i
if dp[i] > best_len:
best_len = dp[i]
best_center = i
return s[best_center - best_len : best_center + best_len + 1].replace('#', '')
時間空間複雜度
假設字串的總長度為 n
時間複雜度 : O(N)
雖然看似有兩層迴圈,但每次迴圈一定能找到大回文字串,假設長度為 m,然後可以一直跳過中間的,直接從該字串的右邊界開始繼續迴圈。那麼約需 n/m 次這樣的迴圈即可。而確定 m 的長度需要內迴圈 m 次。這樣來說,總時間複雜度是 (n/m)*m ,也就是 O(N)
空間複雜度 : O(N)
只需要一個 list 來記錄所有的字母的回文半徑,故空間複雜度為 O(N)