
System Design: Database Scalability
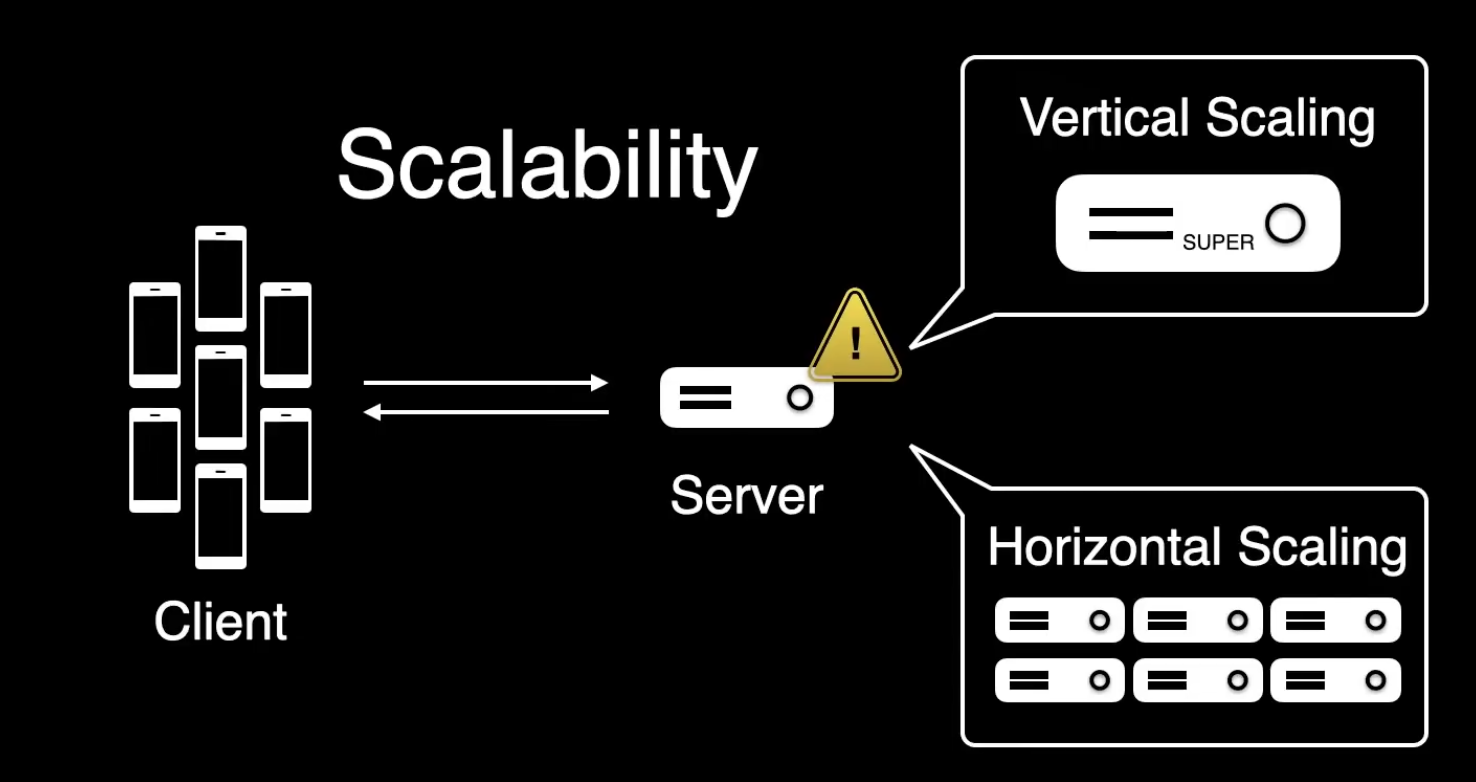
一旦使用者逐漸增加,線上應用流量開始因為業務而持續上升,多到系統無法承受時,就需要讓系統具備擴充能力,來要關注怎麼樣去做 scaling,或者說可伸縮性 Scalability ,其中又有「垂直擴充 Vertical scaling」 和「水平擴充 Horizontal scaling」 兩種擴充方向。 Vertical scaling 是直接給機器換上像是更強的 CPU、更多的記憶體、更大的硬碟等等,但這個通常不是系統設計想考察的 ; 通常說的 Scalability 都是指 Horizontal scaling(簡稱 Scaling),而此方式可以細分成以下三種方法 :
- 增加副本 replication : 將資料複製成多份 Scale Cube ,放在更多的地方
- 資料分區 sharding : 會在每台機器上會保留一部分資料
- 功能分區 functional partitioning : 將一個系統按照功能,去拆分為更小的子系統,也稱 Federation
線上 Application 在現今時代,經常可藉由 cloud 擴展機器或者容器化技術如 k8s pod 擴容等等來應對高流量,但當這樣做時,若還是只有一個資料庫時,則多個 server 服務同時向單一資料庫做操作還是會不堪負荷。故 Database 也會需要 Scaling,這基本上主要有兩個方案 :
- replication
- sharding
Replication Database
Data Replication 是標準的增加副本方式,代表會在多個不同的機器上儲存相同資料。例如說 : 設定一台 MySQL 的伺服器為 Master ; 另外其他多台伺服器作為 Slave。
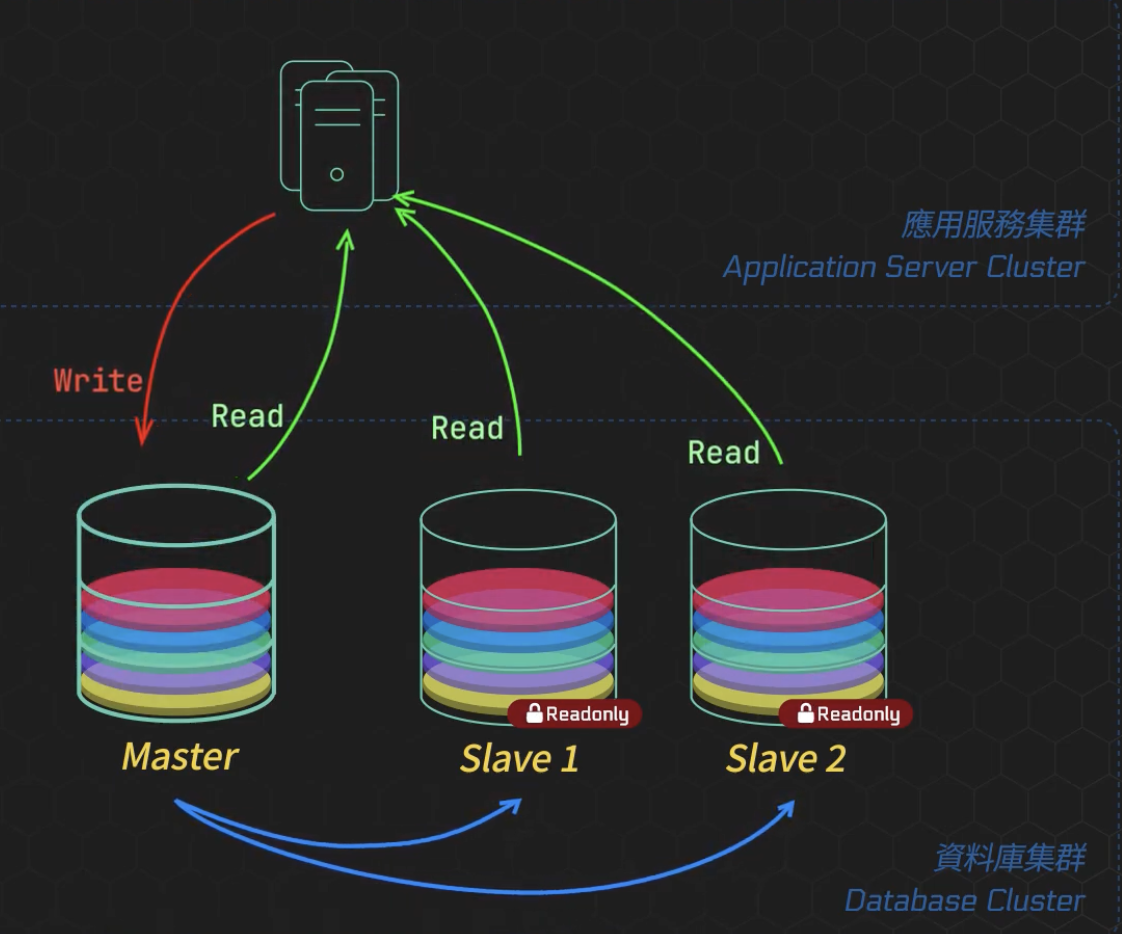
這時定義「寫入只能是 Master 資料庫」,而 Master 會實時將變更,通過異步方式同步到 Slave 中,確保 Slave 也有完整的業務資料 ; 而讀取資料的 request 可以分攤到 Master 和多個 Slave 上,從而減輕了單一 DB 的壓力。
Master 資料庫只有一台,故存在「單點故障 (Single Point of Failure,簡稱 SPOF) 的風險
以上就是「讀寫分離」架構,可以發現有兩個關鍵點:「主從資料同步」和「request 流量分配」。
主從資料同步
一般來說當 Master 執行更新操作,會做 :
- 先修改自己 Memory 中的 data
- 記錄 Redo Log
- 寫入 Binlog
- 最後提交事務,然後返回給客戶端說完成了
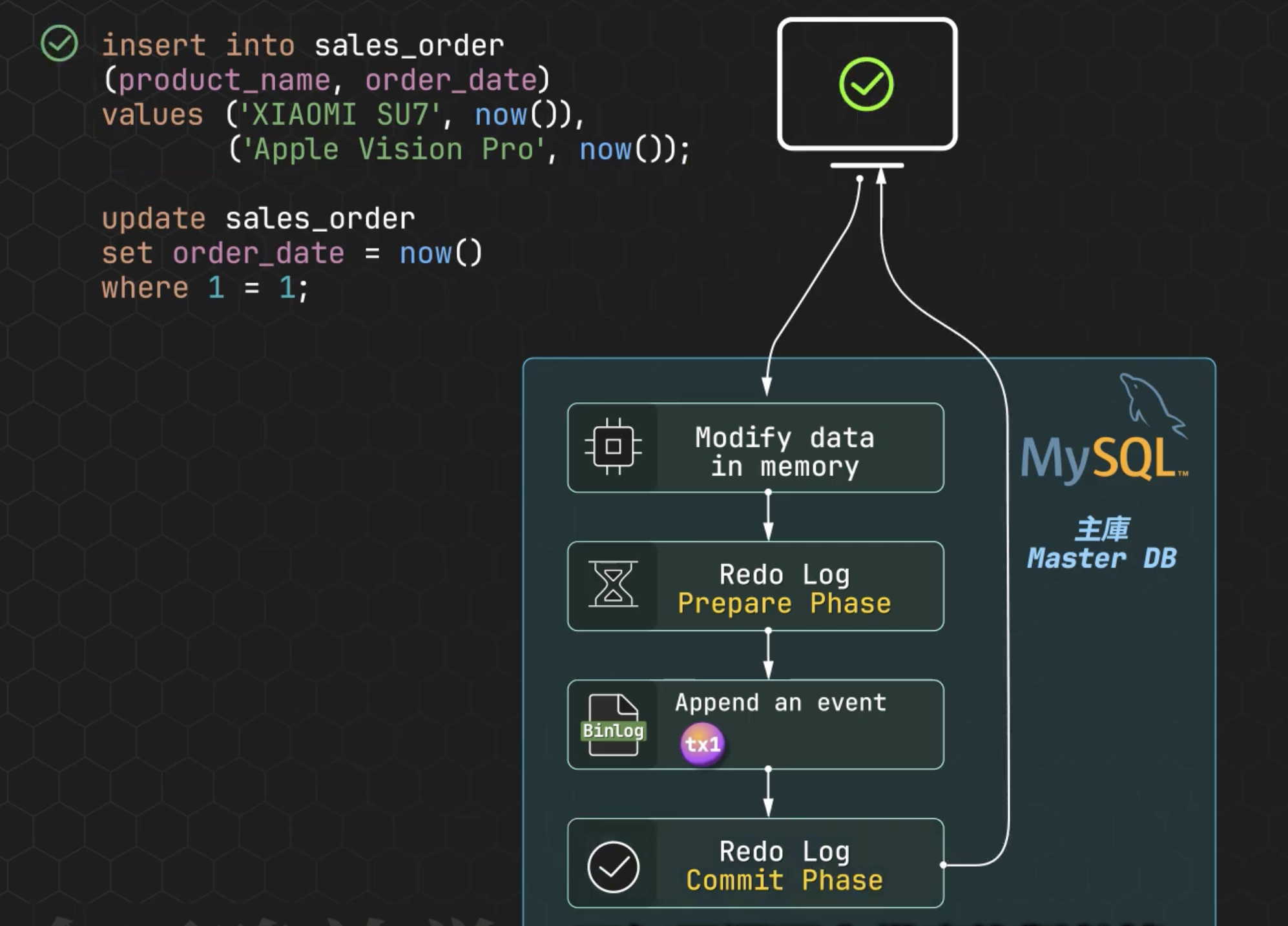
如果還有 Slave 需要 sync 資料,這時主要是 Binlog 會發揮作用:
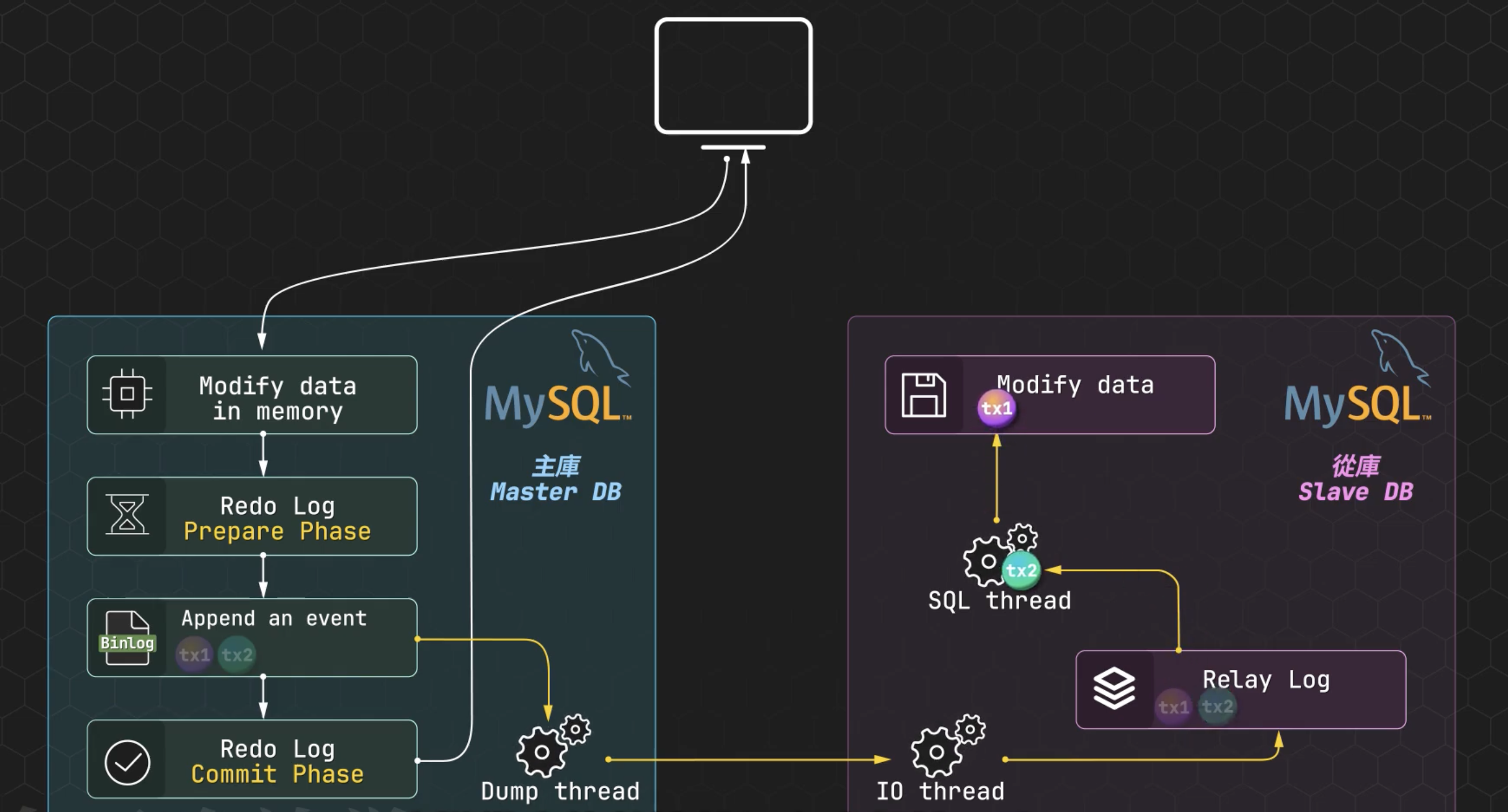
讀寫分離主從資料庫同步的做法,都是 Master 會把自己的 Binlog 實時發送給 Slave 來完成:
- Dump thread 會獲取 Master 最新的 Binlog 記錄
- Dump thread 通過長鏈接,把 Binlog 記錄推送給 Slave
- Slave 的 IO thread 將 Binlog 記錄寫到 Relay log 緩衝區來平衡兩邊的速度
- Slave 的從 Relay log 中讀取內容,並在 Slave 回放
Binlog 完整的記錄了數據庫的所有操作和狀態:
- 保留 SQL 執行語句
- 保存 data 的前後狀態
現今常說的「資料庫復原」,底層關鍵都是使用 Binlog 將資料恢復到誤操作之前的狀態
Replication 提高了可用性(availability)和容錯能力(fault tolerance) ,但同時也使一致性(consistency)和協調性(coordination)變得複雜。注意 Binlog 的傳送是有延遲的,所以 Master 上的操作一定短時間內無法立刻反映在 Slave 上。解決最常用的方式是繞過問題的核心:
在某些場景下,可以讓讀操作也強制在 master 上來執行。
比如用戶自己下的訂單就在主庫上查詢,讓接單的商家去查從庫,反正商家晚幾秒收到訂單問題也不大
通過業務流程故意耽誤一點時間。例如做個假的讀取動畫,為同步爭取更多時間
引入 cache,在寫入的同時更新緩存,如果短期內再次使用相同的資料就從緩存中快速獲取
設定「半同步模式」,等到至少一個 Slave 回饋確認之後, Master 自己才提交事務然後 response 跟用戶說完成了。
這個做法只是機率上降低查詢不到的問題。因為查詢的 Slave 不一定是剛剛半同步模式確認響應的那一台 Slave
以上做法,其實都是在系統「局部偶爾發生」資料不一致時的解決辦法。要是主從一直有延遲,出現長時間的 Master 領先,而 Slave 始終慢半拍無法與 Master 完全一致的情況該怎麼做呢?
絕大部分場景中,其實並不苛求 Master/Slave 的絕對一致,而是只要確認剛剛對 Master 的某項更新,是否已經在 Slave 中反映出來就可以了,舉例如下:
-- 若在 Master 上執行某個 update 操作
insert into sales_order (product_name, order_date) values ('item1', now());
-- 立即執行下面 CLI 以此獲取 MASTER 資料庫內 Binlog 的 info
SHOW MASTER STATUS\G;
-- 例如得到下面這個
-- *************************** 1. row ***************************
-- File: binlog.000035
-- Position: 23597685
-- Executed_Gtid_Set: 8a4fefaa-a5d4-11ee-b295-c46516bca2d4:1-40035
-- 再來換到 Slave 上執行下面檢測函數,確認是否讀取 Binlog
SOURCE_POS_WAIT('binlog.000035', 23597685, 1);
-- 例如得到回傳結果 >= 0,表示在等待時間內已經同步到該位置;回傳 -1 通常表示逾時
-- 如果開啟了 GTID,也可以在 Slave上 執行
select wait_for_executed_gtid_set('8a4fefaa-a5d4-11ee-b295-c46516bca2d4:1-40035', 1);
-- 如果已經套用完成會回傳 0;逾時回傳 1。
request 流量分配
流量分配就是 DB 的 Load-balancer,常見的方案有:
Database proxy 中間層代理
常見的一些自研或者開源的資料庫中介層軟體如 proxysql 等等,其可以根據預設的規則 rule ,將流量引導至合適的 DB 節點。
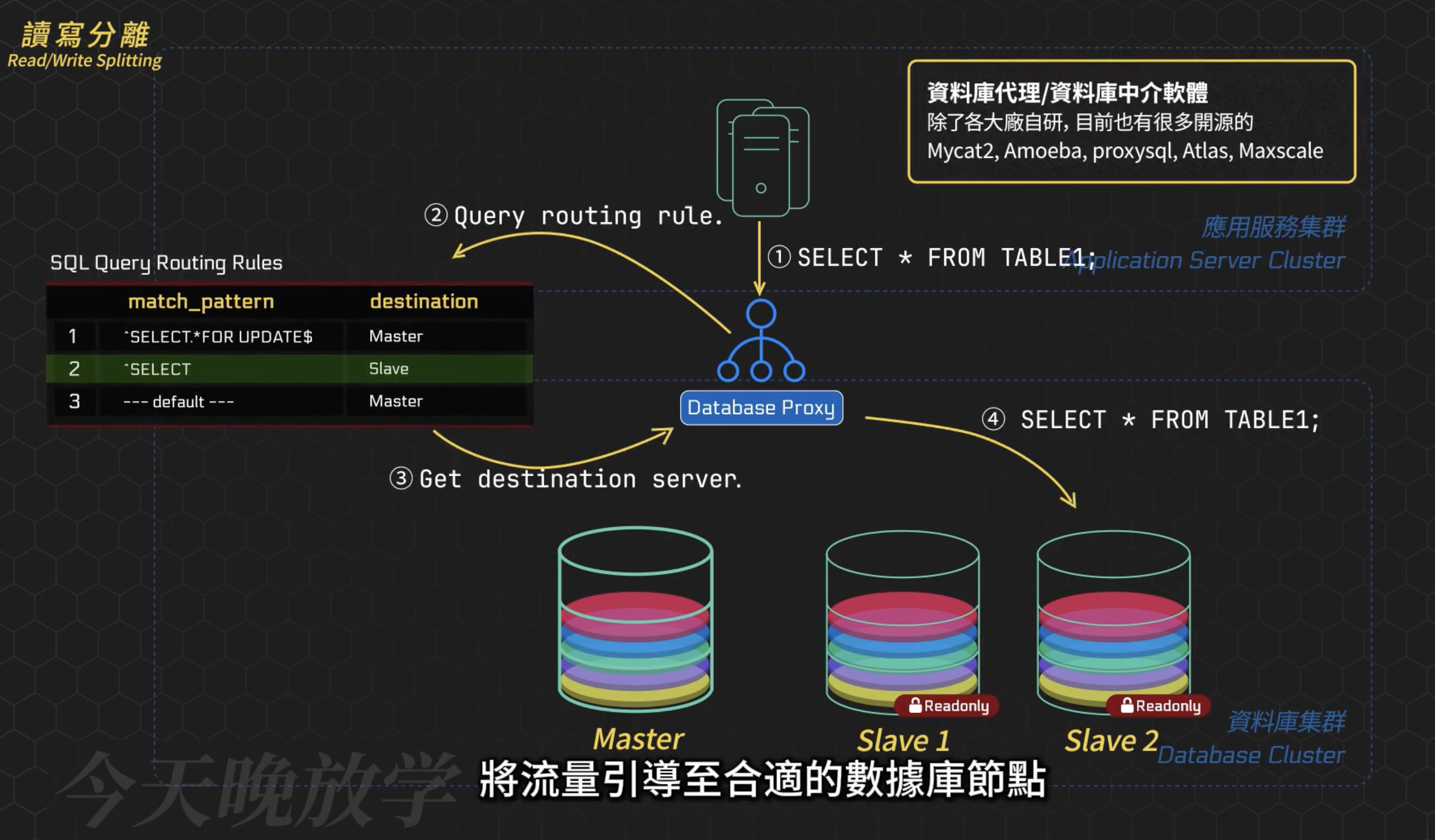
最大的好處是 DB-cluster 對業務而言集群變得透明,感覺還是和單獨的一台 DB 交互。
別忘了 Database proxy 中間層代理的高可用設計,避免「單點故障」的風險
應用程序 code 層面來實現流量分配 在 code 中定義每個 SQL 請求都需要決策是走 Master 還是 Slave。
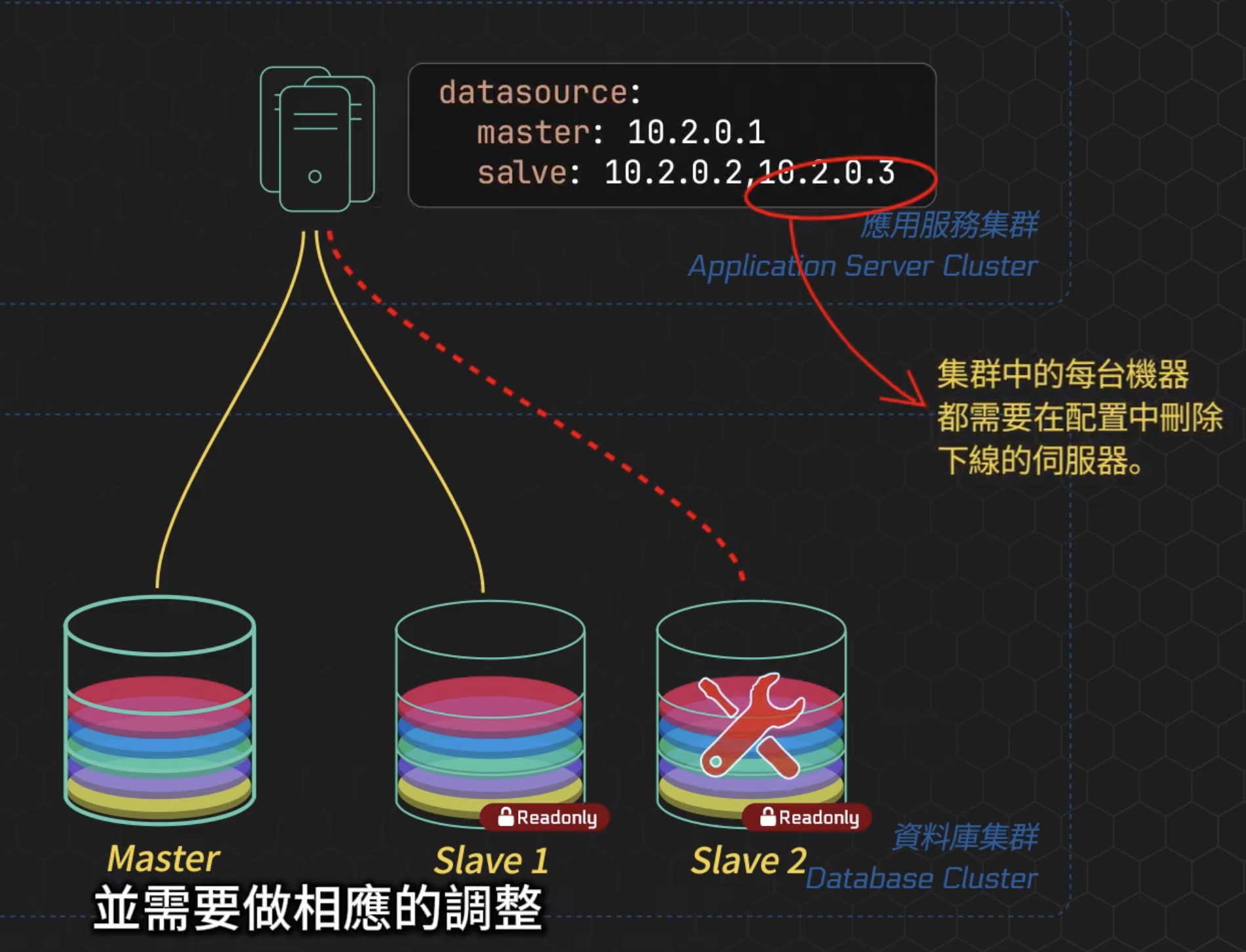
這裡要注意若有資料庫「主從切換」、「故障遷移」的情況下,需要做相應的調整,例如說: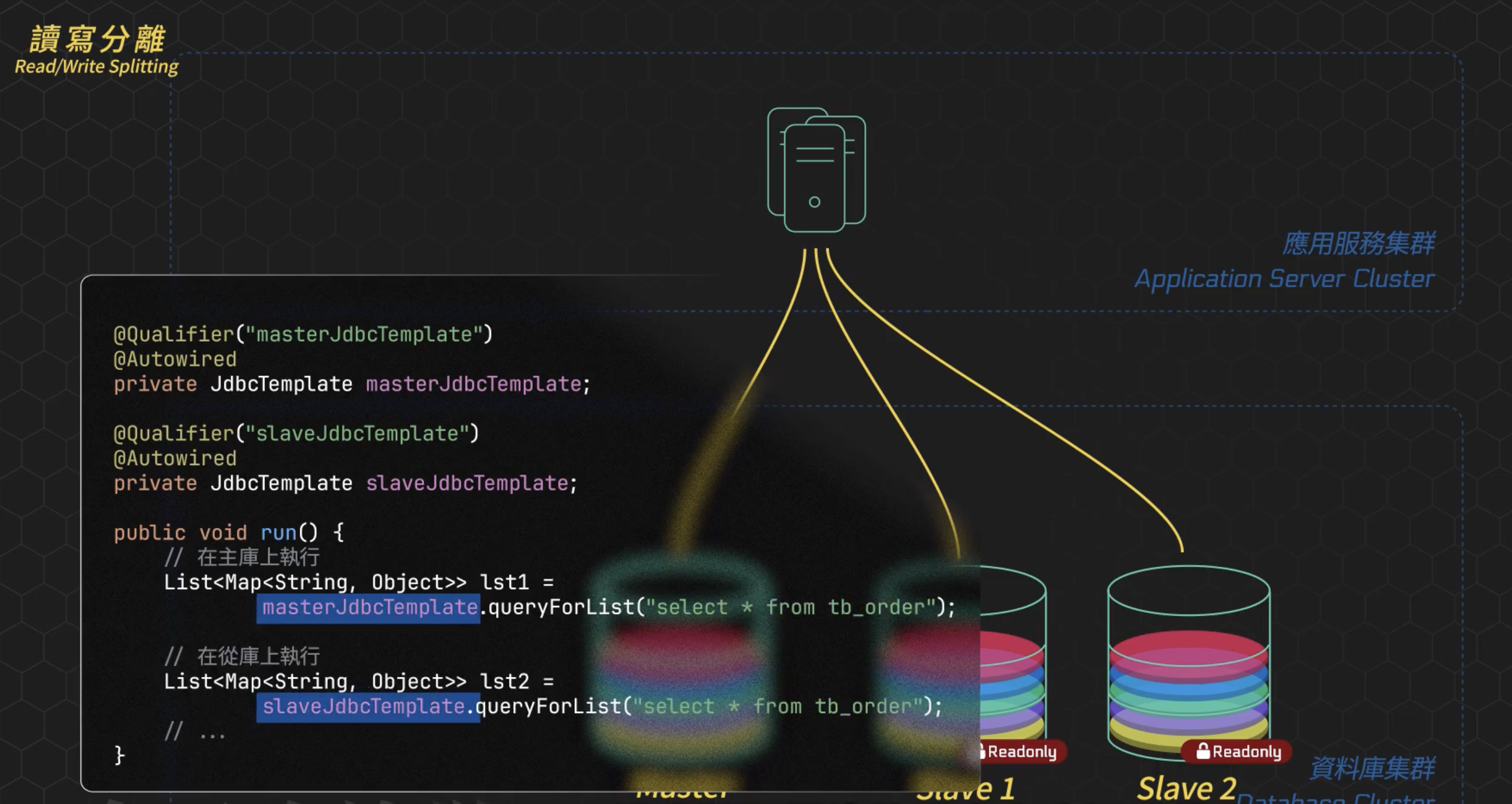
- Config 設定,要把下線的機器 ip 拿掉,可能需要手動操作
- 可以藉由 ZooKeeper 統一自動管理 Config 設定 確保一致性
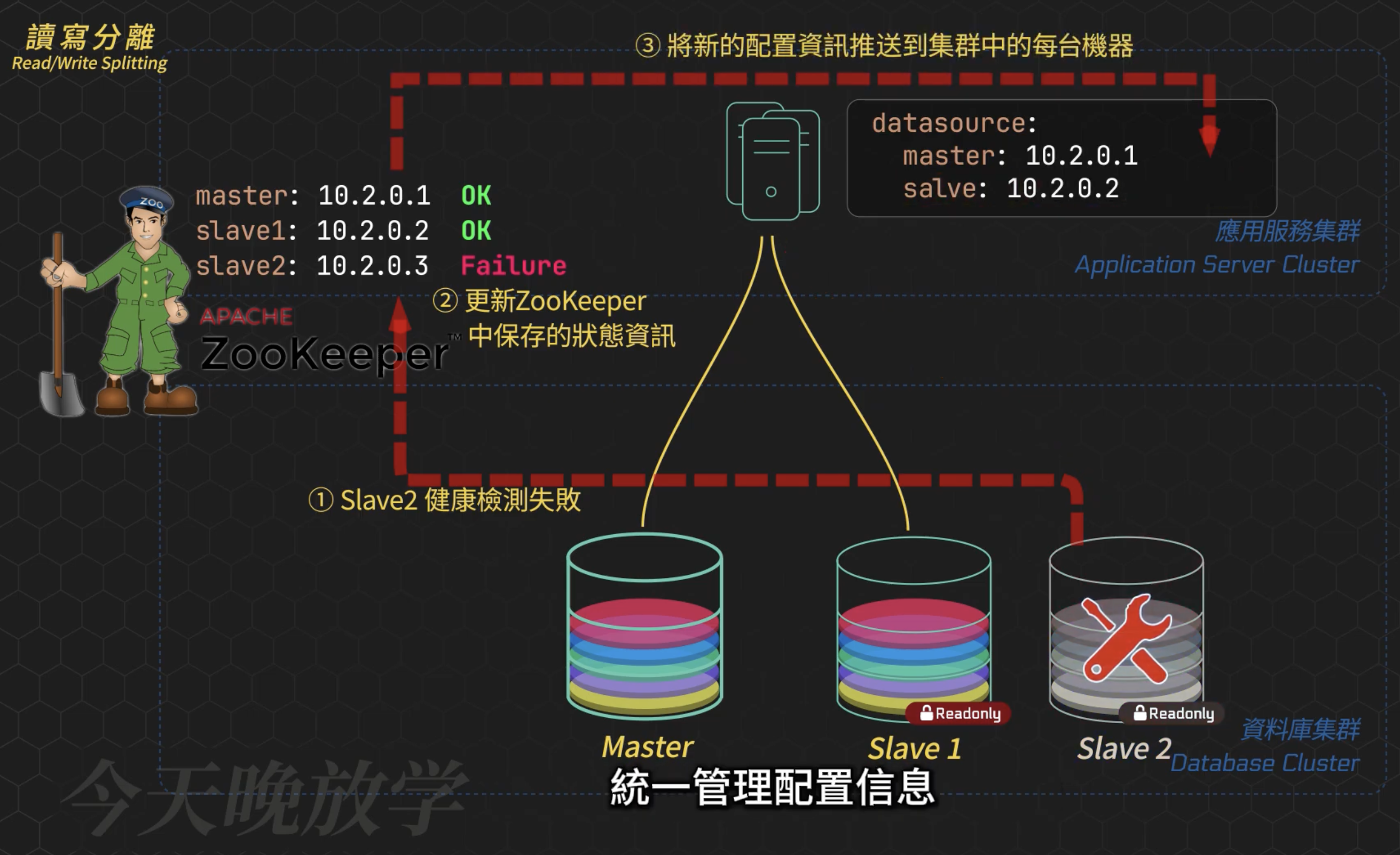
- Config 設定,要把下線的機器 ip 拿掉,可能需要手動操作
增加多台機器的另外一個好處,就是增加了可靠性 reliability,即使其中一台不幸掛掉,也還有其他機器能持續運作,甚至遞補上來,因此能避免單點失效 single point of failure
Sharding Database
讀寫分離架構下,僅適合大量讀、少量寫的情境,雖然能有效降低讀取的壓力,但是仍然是「單一主機寫」的架構,面對大量寫入流量或者單表上億的資料量,還是沒辦法解決的。在這個情況下就需要引入 「Sharding」 的機制,這也可以被叫資料庫分割 (database partitioning)。
所謂 Sharding 的意思,就是把原本集中在一台機器的資料分散放到多台機器上,對應之前說到的資料分區(Data Partition)分類。當需要存取或讀取資料的時候,可以只操作擁有對應資料的分片,而不需要跟所有機器進行通信。其中又有「垂直分散 vertical sharding」 和「水平分散 horizontal sharding」 兩種方向:
Vertical sharding 就是把不同公用的 table 放到不同的機器上,把資料庫按照 功能分區 進行分庫,例如用戶、訂單、產品、等業務類型進行拆分。額外的好處是即使個別 Database 發生故障,也能有效隔離不同業務也同時受創的風險。
Horizontal sharding 則是透過某種規則,將同一個 table 的不同筆資料打散到不同的機器上。隨著業務的發展,即使是單一業務也可能達到單台資料庫處理的上限,這時就可以開始考慮這樣的「橫向拆表」。一般情況下,好的 sharding 規則能讓達到最極致的分散擴充效果。
一旦決定了要拆分 Data,可以研究一些中間件比如說 ShardingSphere ,它能夠將眾多分表,模擬成單張虛擬表,讓過程方便不少
將每個業務封裝成個別服務之後,架構上就可以根據自身的業務性質,設計自己的 cache、master/slave、ratelimit,甚至再一次分庫分表都可以。
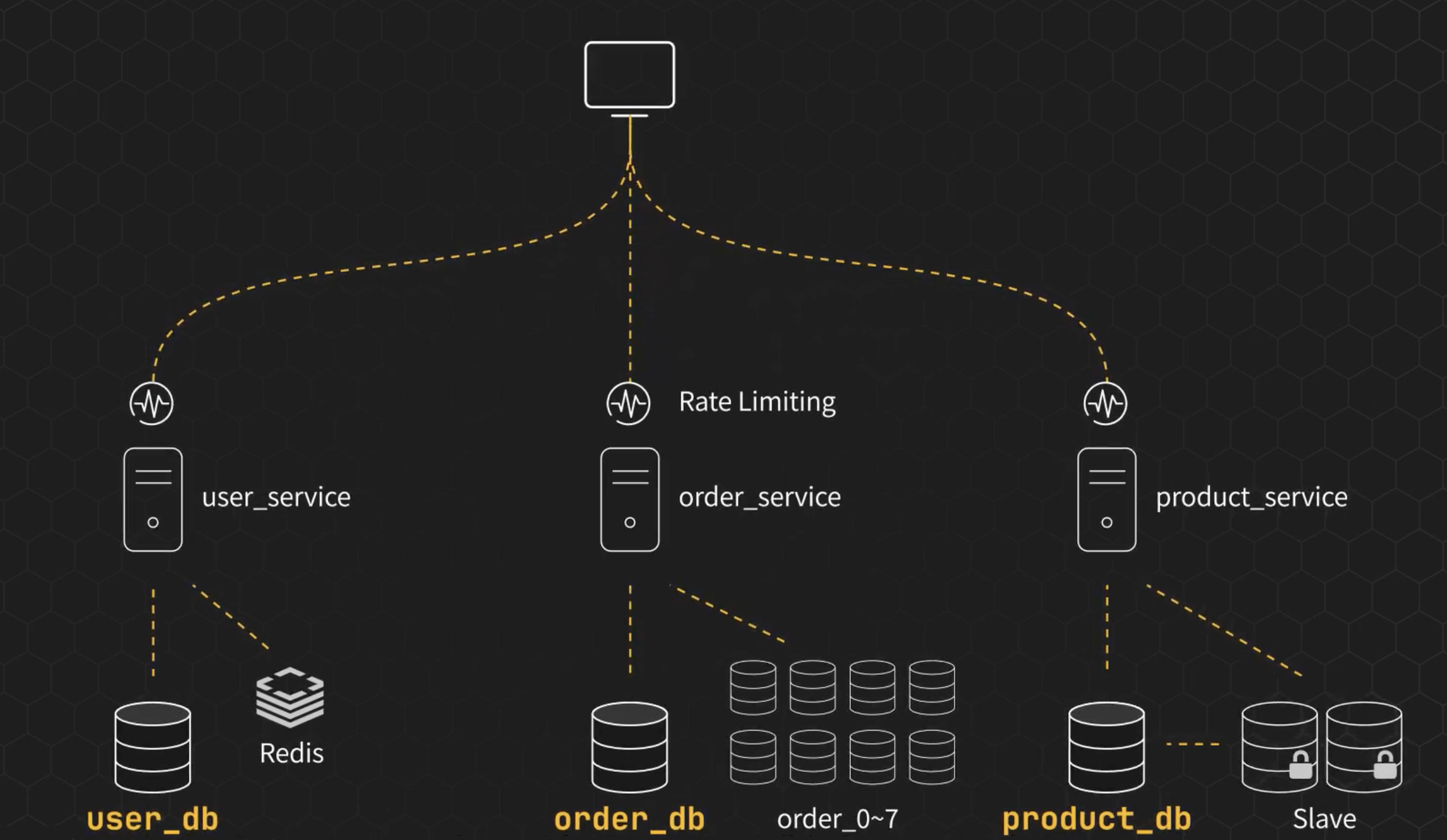
Sharding 策略
考慮如何選擇 Sharding Key,其關鍵是需要兼顧:「資料平衡」、「擴展性」、「維護性」、「避免單點」 這幾個方面。例如就使用 X-Twitter 的貼文 Post 來當範例,Post 的 Table 當中包含了兩個 ID:
- Post 本身的 ID,稱 post_id
- Post 對應的 author 的 ID,稱 user_id
這裡 Sharding Key 就能有兩種 rule 規則可以考慮,各自有它的優劣勢:
根據 post_id 去做 Sharding
通常還是比較推薦使用 post_id 這種 itemID 來當 Sharding Key ,好處就是可以 uniform distribution 分擔負載 ; 壞處是會需要查詢多個 shard ,才能得到 user 發的多個 Post,但這種 latency 問題很大程度上可以靠 cache 解決。
需要把這個 request 發到所有的 shard 上,然後每個 shard 的運算完後將這個結果回傳,並在應用層去進行一次聚合,這個模式叫做「scatter and gather」
根據 user_id 去做 Sharding
選擇 user_id 的話,一般會有 Hotspot 風險,比如說 X-Twitter 有一個大戶 user,有大量的 Follower,然後這人又非常喜歡發帖,那麼同一個用戶所有的發文就會被存在同一個資料庫上,其大量的追蹤者可能會導致頻繁 request 單一 database 造成大量的負載。
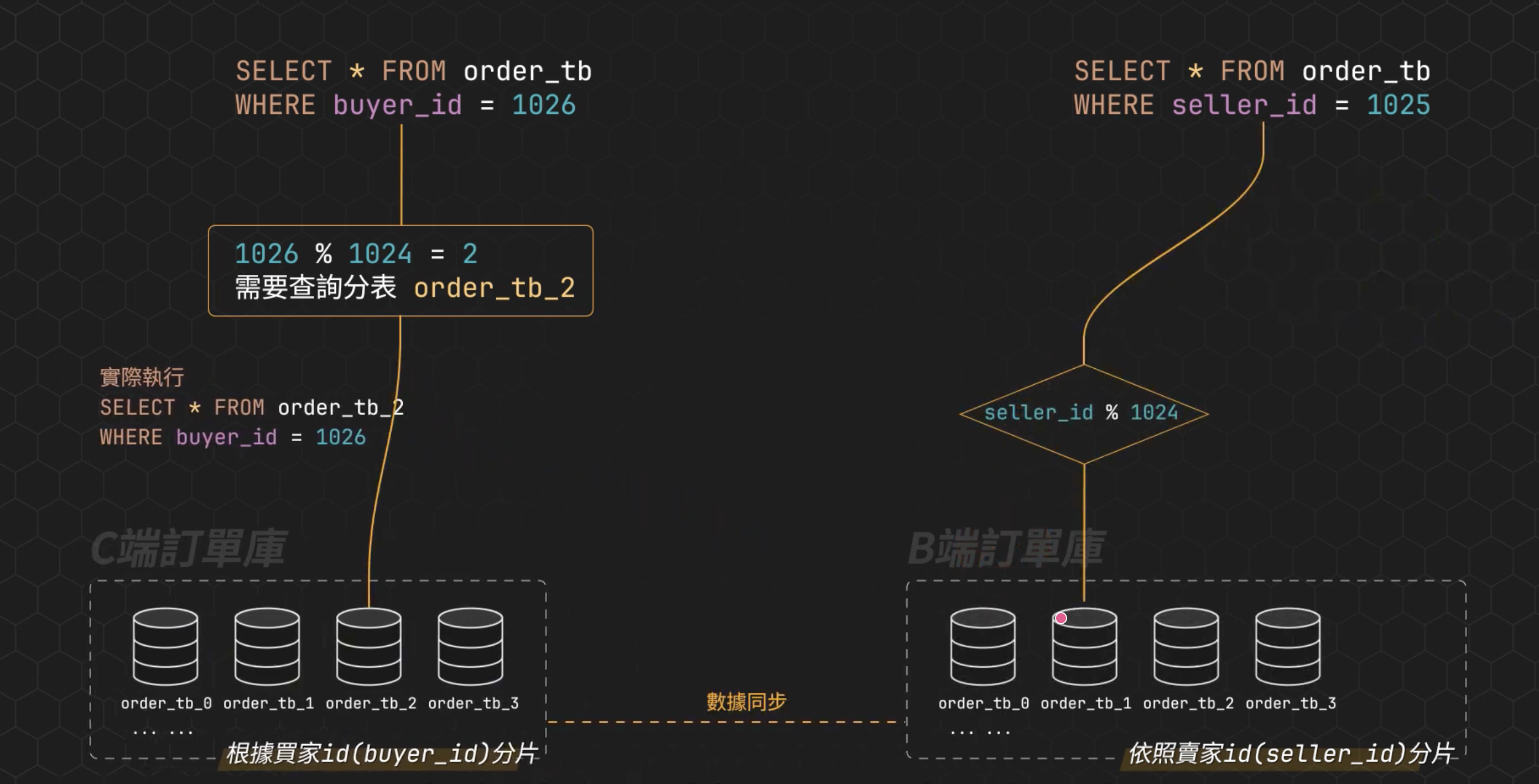
上面的優缺點分析是很普遍會遇到的,但有蠻多時候其實可以兩種同時使用的。例如說用電商平台舉例 : 有「C 端 order_tb_cluster」 資料庫集群,裡面有 order_tb_$, $: 代表某個 sharding,然後其資料庫內的 Table 裡面有兩個重要的 id 分別是 buyer_id 、 seller_id 。
首先「C 端 order_tb_cluster」是對 buyer_id 進行了 sharding ,這樣雖然非常方便讓使用者查詢自己的訂單,但對商戶端卻帶來麻煩,因為每個商家的訂單都會被打散到多個 sharding 上。
這時可以另外部署一個 「B 端 order_tb_cluster」給商戶端使用,這邊是按照 seller_id 進行 sharding,然後資料是 「C 端 order_tb_cluster」 同步給 「B 端 order_tb_cluster」。
在這個設計下,「C 端 order_tb_cluster」是有機會遇到 hotspot 的。例如說某個著名公司訂單體量巨大,會造成某些分片熱度過高,這時常用解決方式是建立 top_seller 對照表,那些著名公司就為他們準備一個性能超強的的單表資料庫,或者是獨立的資料庫集群。
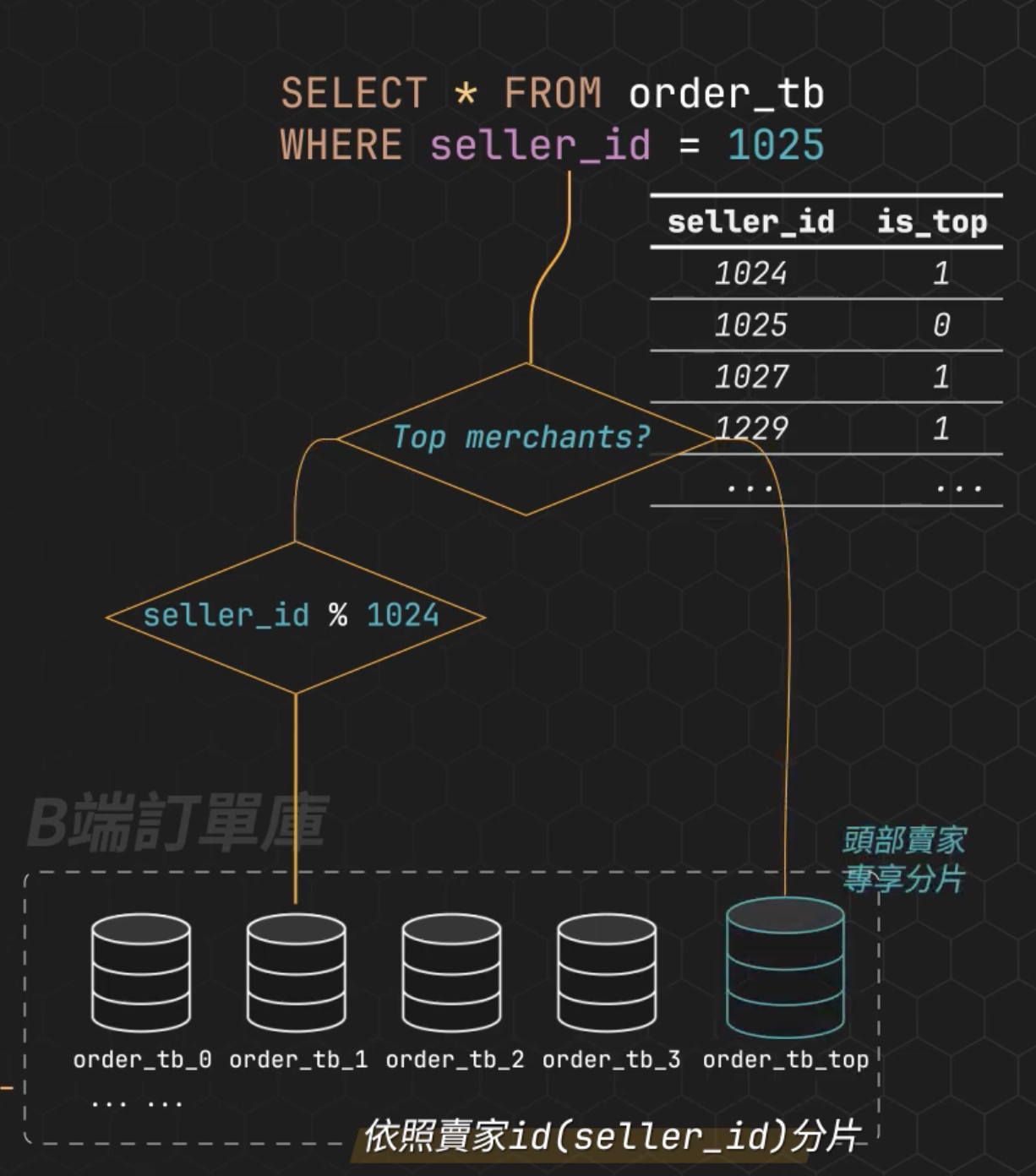
要注意不要讓 top_seller 對照表,形成「單點故障」
從上面分析其實可以感受到,隨著業務形態不同,分庫分表的方式可以非常多元,例如說 :
- 可以使用 city_id 來 sharding : 熱門城市可以獨占一個表或者一個庫,而那些冷門城市就 就放在一起擠一擠
- 可以根據「時間年份」做拆分,定時建表定時刪很方便,Query 時間段的資料也非常迅速。但 Hot/Cold data issue 會非常明顯,最近創建的 Table 會有非常高的 read/write qps ,可能產生各種各樣的問題
- 真的追求平衡無熱點,可以按照主鍵 Hash 來拆分
Sharding 之後的問題
Sharding 之後如何保證 primary-key 在所有分表都全局唯一呢?
通過程式生成主鍵 ID 是最常見的方式,說到生成不重複的 ID,最容易想到的是 UUID,比較要注意的是 UUID 生成的順序完全隨機,為了解決此問題「雪花算法」就應運而生。

64-bit long 拆成三段:1 bit:符號位,固定為041 bits:時間戳(毫秒)12 bits:買家標識8 bits:隨機數
雪花算法的思想還蠻重要的,因為可以定制自己的主鍵生成策略。比如訂單表中,無論是按照 buyer_id 還是 seller_id 來進行 sharding,假如就是想透過 order_id 訂單號來查詢訂單詳情呢?
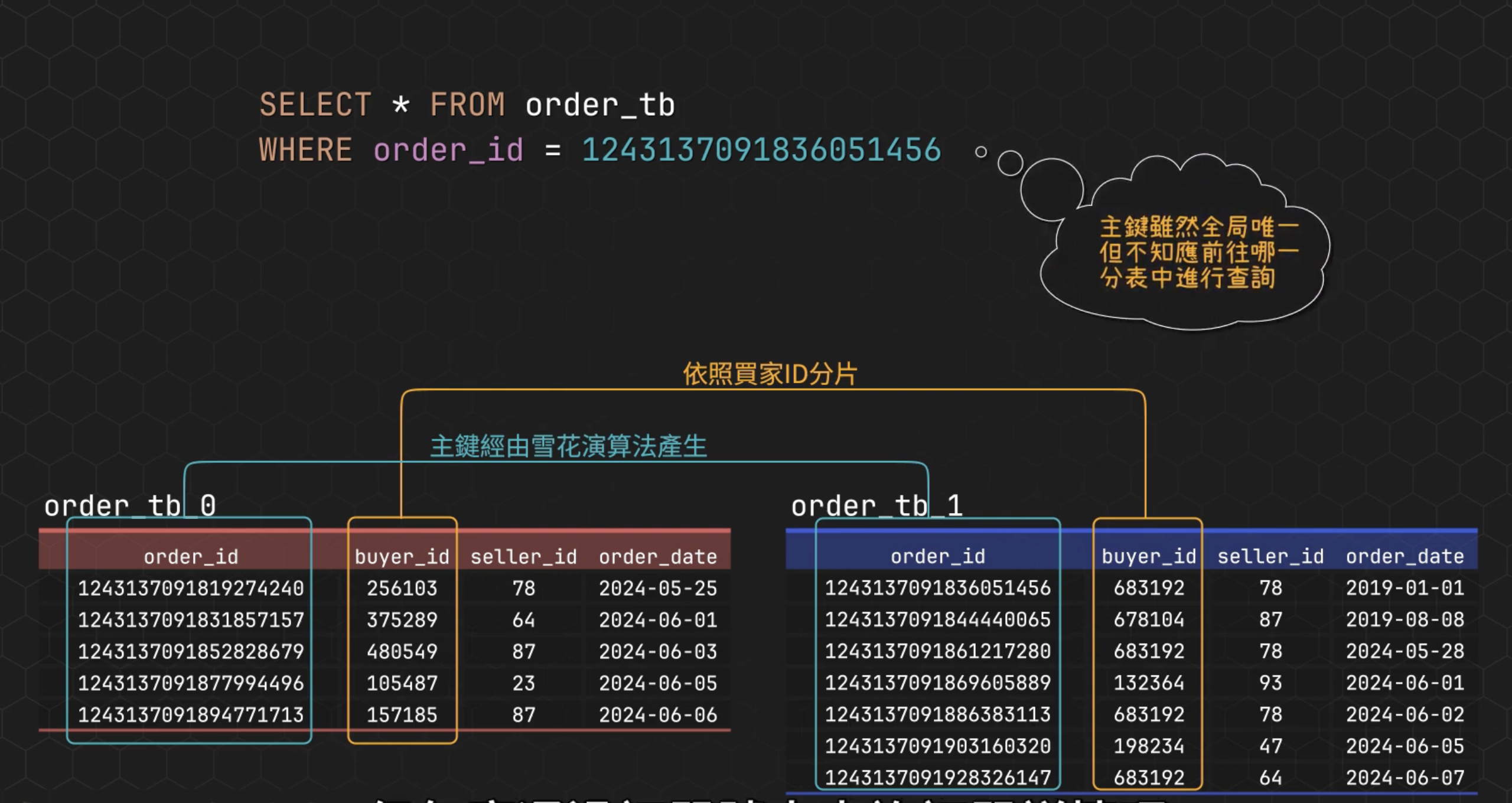
解決方式可以將 sharding-key (例如 buyer_id)嵌入到主鍵中 :
0 - [41位時間戳] - [buyer_id] - [8位隨機數]
long orderId = ((timestamp - twepoch) << 20) // 時間戳
| ((buyerId & 4095) << 8) // buyer_id
| randomNum; // 隨機數
long shardId = (orderId >> 20) & 1023;
使用 orderId 檢索的時候,可先從 orderId 中解析出 buyerId ,這時候就可以找到對應的 sharding 進行查詢。
Query
無論是「把資料庫按照 功能分區 進行分庫」或者是「把儲存 data 進行資料分區 Sharding」,導致的一個最常見一個問題就是:沒有辦法簡單的透過 SQL 來實現一次性查詢的功能了,會需要進行跨分片查詢。
例如說進行分庫之前,原先一個直截了當的 SQL 語句 :
select ord.sales_order_id, ord.order_date,
p.product_name, u.user_name, a.full_address
from sales_order ord
left join product p on ord.product_id = p.product_id
left join user_info u on ord.user_info_id = u.user_info_id
left join order_address a on ord.order_address_id = a.order_address_id
where ord.sales_order_id = 40041;
分庫之後查詢資料會需要調用眾多介面,最後要拼湊結果,但這時進一步可以採用「並發呼叫」的方式 :
// 使用 org.springframework.web.reactive.function.client.WebClient 進行異步調用各個服務
val salesOrderId = 40041
val salesOrderUrl = "/SalesOrder/$salesOrderId"
val salesOrder = webClient.get().uri(salesOrderUrl).retrieve()
.bodyToMono(SalesOrder::class.java).block()!!
val orderAddressUrl = "/OrderAddress/${salesOrder.orderAddressId}"
val orderAddressResp = webClient.get().uri(orderAddressUrl).retrieve()
.bodyToMono(OrderAddress::class.java).onErrorReturn(emptyOrderAddress)
val productUrl = "/Product/${salesOrder.productId}"
val productResp = webClient.get().uri(productUrl).retrieve()
.bodyToMono(Product::class.java).onErrorReturn(emptyProduct)
val userInfoUrl = "/UserInfo/${salesOrder.userInfoId}"
val userInfoResp = webClient.get().uri(userInfoUrl).retrieve()
.bodyToMono(UserInfo::class.java).onErrorReturn(emptyUserInfo)
val t = Flux.zip(orderAddressResp, productResp, userInfoResp).blockLast()!!
val result = OrderDetail(salesOrder, t.t1, t.t2, t.t3)
- 由於沒有依賴的查詢可以同時並行,整體響應速度甚至可以比原來的 Join 查詢還快
- 使用
.onErrorReturn就可以簡單實現服務的「故障隔離」讓非核心應用的故障僅導致「服務降級」,比如頁面上的某些內容顯示不完整