
Avro
Avro 是一個 data serialization 框架 ,是 Apache Hadoop 下的一個子項目,是一個可跨多種程式語言和平台的傳輸資料格式。Avro 可使用 JSON 格式來描述 data structure,並且支持架構演進,保持向後、向前的相容性。 Avro 也提供了編解碼和二進制格式,使得在高吞吐量的應用場景中非常有用且高效。
Avro schema
Avro 序列化首先要先定義 .avsc file ,通過 Schema 來定義 data structure 可增加通用性。 Schema 用 JSON 表示,以下是一個簡單 Avro schema 範例 :
{
"type": "record",
"name": "User",
"fields": [
{"name": "userName", "type": "string"},
{"name": "favoriteNumber", "type": ["null", "long"]},
{"name": "interests", "type": {"type": "array", "items": "string"}}
]
}
因為 Avro 是 java 寫的,故基本上 Java 能夠支持的 data structure 即爲 Avro 所支持的 data structure
這裡特別提一下 Avro 的 Union 類型,可表示各種類型的組合。比如 ["null", "string"] 表示類型可以為 null 或者string。 Union 類型的默認值,是看 array 的第一個元素,因此如果資料中這個 type 可能會 null 的話,那麼 null 一般都會放在 array 第一個位置,這樣子的話這個默認值就是 null 了。
Union 類型中,記本上不允許同一種類型的元素存在多個,除了 record, fixed 和 enum 。比如 Union 類型中有 2 個 array 或者 2 個 map ,都不允許的。
如果知道 protobuf 的話,這裡可以發現定義的 Avro schema 格式,並沒有在 schema 中使用欄位標籤 (field tags)
接下來拿個實例來分析一下:
{
"userName": "Martin",
"favouriteNumber": 1337,
"interests": ["daydreaming", "hacking"]
}
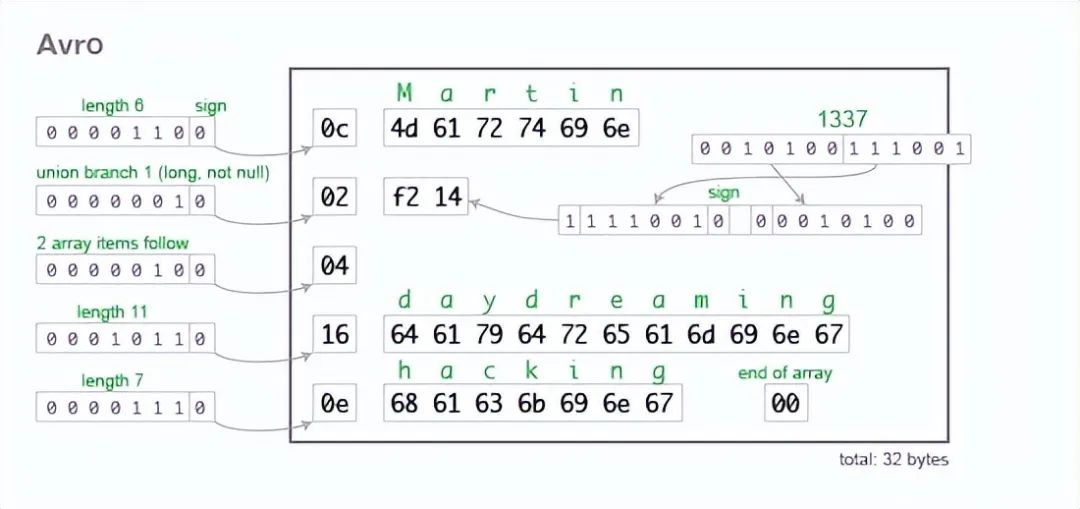
把實例 encoded 後,首先先只看 userName 資訊 :
- 知道長度是 6
- 後面是 UTF-8 字串 byte array
並且發現在 encoded 資訊中,沒有任何其他標示說明 userName 的類型,故從 byte streaming 的觀點,並不知道 userName 會是甚麼型別,可能是一個整數或者完全是其他的東西。
所以能正確解析這個 byte streaming 的話,會需要其他參考,方法就是通過與 schema 一起比對。也就是說在 decoding 資料時,最好使用與 encoded 資料時相同的 schema ,任何不匹配的欄位都有可能會造成 decoding 時不正確。
這邊和 Protobuf 蠻不一樣的。 Protobuf encode 後,byte streaming 有 tag 和 type 等資訊。故不用再和 schema 做比對。
Avro Schema Revision
Avro 提供了高效、跨語言、使用 schema 的序列化機制,但如果 schema 發生變化會怎樣 ? Avro 產生了 reader 和 writer 模式兩種模式,資料寫入與讀取的 schema 可以不同,這讓 schema 可以一直 Revision。
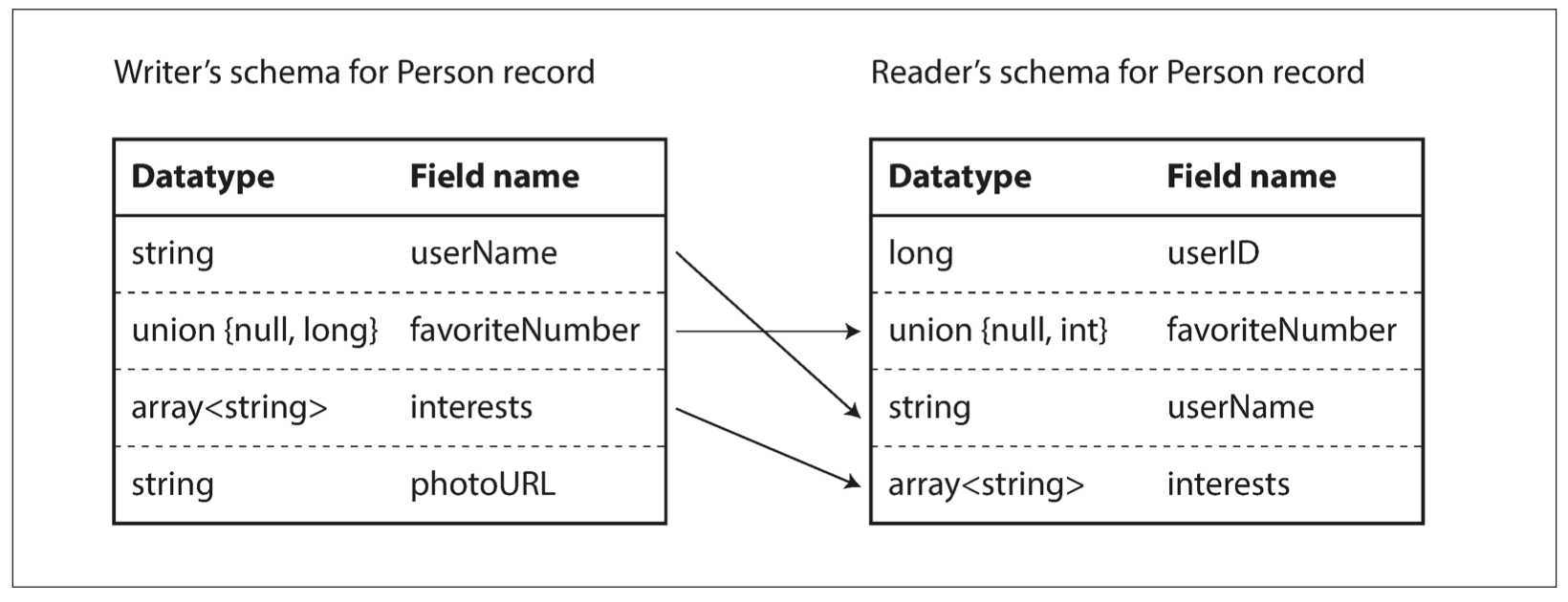
為了保持 revision 前或後的一致性,基本上只能是: 新增或刪除帶有預設值的 field
可擴展性
在某些程式語言,null 是可被允許的預設值,但它不是一個 Avro 用的欄位型態,故要使用另一種支援的方式: union type 來讓預設值設為 null。
Avro encode 中,如果你想 optional 一個 field ,可以使用例如
"type": ["null", "long"]。Avro 沒有像 Protocol Buffers 那樣的 required 和 optional 的標註,取而代之就是用 union 加預設值來實現。
Avro 只要給能給 default 值的話,可以任意添加 field 。
在疊代更新的情況下,默認值是必要的,因為新 schema 的 reader 解析到用舊 schema 寫的記錄時,因為舊 schema 並沒有該值,新 schema 的 reader 可以填入 default 值來代替,避免錯誤。
同理,要刪除一個 field,只要它以前有一個默認值的話就可以很方便的刪除。
若想保證 rollback 的情況也不會發生錯誤,默認值也是必要的,因為當要使用舊 schema 的 reader 解析用新 schema 寫的記錄時,因為新 schema 把該值刪除了,舊 schema 的 reader 可以填入 default 值來代替空。
承前的講解,如果某 field 沒有 default 值,以後更新疊代會比較不方便刪除該 field ,所以有種建議,是 avro schema 如果可能的話,所有 field 都給默認值是可以的
前面有提到改變 field name 是有點麻煩的。但改變 field name 也不是不行,但是有點麻煩且解法 tricky。需要把 reader 的 schema 改變後欄位名取 alias name (別名)
向新版本兼容沒問題,但向前兼容就無法兼顧了因為,舊 reader 遇到不認識的 schema 會忽略。
Serialization
Avro 進行序列化和反序列化有兩種方式,以下用 java 舉例 :
根據
.avsc來 generate 出對應的 code structure,這樣在 java 中就可以使用builderfunction,來建立 data使用 Parser 讀取
.avsc,得到對應 schema,接著使用GenericRecord,用法和 java map 操作類似,可建立 data
這裡比較要注意的是, 當 schema 中接受 null 的情況 :
使用自動生成對應的 code structure,似乎比較不容易發生 org.apache.avro.AvroTypeException 錯誤。因為用 builder 時,在 java 中物件處理就對 null 有比較高的支持度了。
而使用 Parser 讀取 schema , Avro 解析 json 文件的時候,如果類型是 Record 並且裡面有 union 且允許 null 的話, data 轉換成 json 文件的時候要寫成例如這樣才不會有誤:
{
"name":"Martin",
"favorite_number":{"int":1337}
}
需要這樣寫的原因也很簡單,這種寫法確定了 data 的唯一 type ,不會發生歧異。