
Protobuf 簡介
Protobuf 全稱 Protocol Buffers ,是一種輕量級的資料交換格式,最初是由 Google 開發的「可擴展的序列化資料結構」,現已成為一個開源項目,其語⾔中⽴且平台無關,適合高性能且對響應速度有高要求的資料傳輸場景;也因為有資料壓縮的能力,故也可用於資料儲存。Protobuf 的核心思想是先定義好 data schema ,然後可根據所需的語言生成對應的 code base,方便使用者操作 :「序列化寫入、反序列化讀取」。
Profobuf 需要注意的缺點是為二進制格式,故編碼之後不具有可讀性,需要反序列化後才能看得懂資料內容 ; 雖然是個好東西,但並非是個用來完全取代 JSON 的解決方案,JSON 仍有其可讀性高、易操作及通用性高等優點,在多數 API 設計的場景之下,JSON 仍然是最好的選擇。
Protocol Buffers 做為一種資料交換格式,主要有兩個面相:
- 定義了一種介面描述語言 (Interface Description Language,簡稱 IDL),用來描述需要交換的資料結構
- 定義了一種 serialization-deserialization 模式
本章節主要說明其中的 「Interface Description Language」,和介紹一些專有名詞。
Protobuf schema
首先介紹 .proto檔,以下是一個簡單 schema 範例,用來說明一些名詞定義和解釋 :
syntax = "proto3";
message Author {
optional string name = 1;
optional int32 age = 3;
repeated string interests = 5;
reserved 2, 4;
reserved "foo", "bar";
}
一個
.proto檔案中,可以定義一個或多個 message。optional string name = 1;類似這樣的結構,稱為 field。field 內我們有看到
optional、repeated等等,這些稱為 label。field 內我們有看到
string、int64等等,這些稱為 type。比較特別的是 Message 也可以是一個 type。Protobuf 允許一個 Message 是另一個 Message 內 field 的 type,使之可以來表達更為複雜的資料結構。
再來我們看到每個 field 都有定義一個數字,我們稱 field number,它的作用是在二進制格式中,用來識別(identify)欄位,一定要 unique,最小值為 1。
Reserved:
當刪除或註解掉 message 中的一個 field 時,將來其他開發人員在更新 message 時,可能會不小心重複使用到先前的 field number,將會導致嚴重的問題如資料反序列化損壞。一種避免問題產生的方式就是使用 Reserved,它可以保留已用過的 field number 或 field name,如果將來有人不小心誤用了,在編譯 proto 的時候,編譯器就會報錯。
注意不要在 reserved 中把 field number 和 field name 一起混用,要分開寫。
Protobuf 有 proto2 和 proto3 版本,現在一般都使用 proto3,如果不指定 proto3,預設使用會 proto2 ,要寫的話一定要寫在最前面第一行。proto3 和 proto2 主要差別是 proto3 會更優化有 repeat label 的 field,原本的 proto2 在數字類型,例如 int32、int64 等等的 repeated field 沒有高效地編碼。
field number 和 type,合起來稱 Tag ,是 protobuf 最重要的一個標示 !
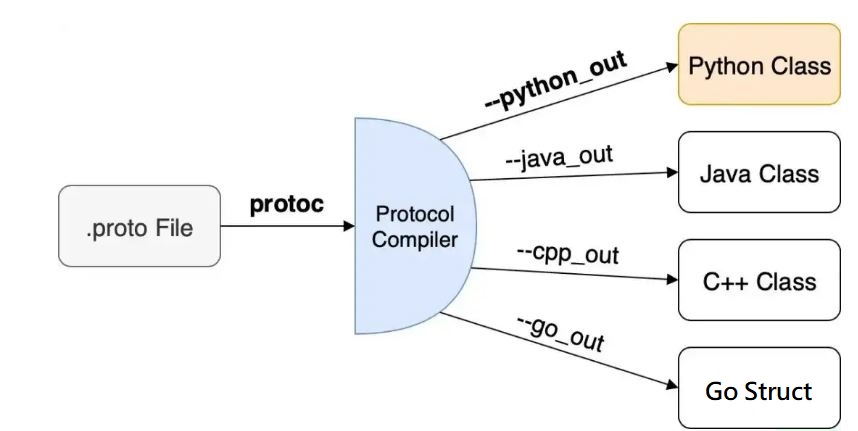
Protobuf 編譯器
一個 .proto 檔,提供了一個標準通用的資料結構和格式定義,可以使用 Protobuf 編譯器,輕易生成 class類別或 struct結構體,讓我們可以在不同的語言之間都可以進行序列化和反序列化。
protoc --version //libprotoc 3.20.1
// 將當前目錄中的所有 .proto 進行編譯以產生 java class
protoc --java_out=./ *.proto
.Proto 命名原則
- 文件名建議全小寫字母加下底線,lower_snake_case
- Message、Enums 外層大結構命名,使用所有單字首字母大寫,PascalCase
- field name 建議使用全小寫字母加下底線,lower_snake_case
- Enums 的 field name 使用全大寫加下底線,CAPITALS_WITH_UNDERSCORES
範例 :
/*
命名方式參考如下
*/
message SongServerRequest {
optional string song_name = 1;
}
enum FooBar {
FOO_BAR_UNSPECIFIED = 0;
FOO_BAR_FIRST_VALUE = 1;
FOO_BAR_SECOND_VALUE = 2;
}
- repeated 類型的 field name 使用複數形式命名
版本兼容性
Protobuf 支援對 Message 進行向前向後兼容,可以在不破壞現有服務的情況下擴充 .proto,但是需要注意一些事項,這裡先不詳細解釋其原理,後續會再慢慢說明,如下:
- 添加新的 field,其 field number 絕對不能重複;但只要是給一個新的 field number 的話,就可以自由添加 field,不用擔心兼容問題。
- 已存在 field number 不能變更,可能會造成後續版本解析錯誤。
- Protobuf schema 可以簡單任意的重新命名 field,不會有任何問題。
Protobuf 在解析時,主要都是看 field number 和 type,因為其實在序列化的二進制資料中,並不存在 field 名稱的標示,在 Protobuf schema 中, field name 其實不太重要。
- 雖然從 schema 中刪除 optional field 是安全的,但要注意絕對不能在未來,讓另一個 field 不小心使用到已刪除的 optional field 的 field number。因為可能有已經存儲的舊的序列化格式 byte array data,這時候若用新的格式反序列化,會造成錯誤。
上述幾點是最重要的觀念,要特別注意,如果做錯了會造成資料解析很重大的錯誤。有個蠻常見 Protobuf 問題 :
可不可以在某個
.proto檔案的中間加一個 field ,然後為了好看編號,把後面所有的 field number 數字都加 1 來 shift 編號呢 ?
答案是不行,絕對不能「使用任何以前使用過的 field number」也絕對不能「使用到一樣的 field number」! 會覺得可以 shift 這樣做的想法,大概是把 Protobuf 想成跟 json 類似,都是用 field name 來當 data 的 Key,所以順序和 field number 不重要。但這是錯誤的!
簡單來解釋原因,是因為 Protobuf 會壓縮資料,資料在反序列化時會對應 field number 和.proto 檔案來解壓縮,但上述的把 “後面所有的 field number 數字都加 1” 的作法,會讓反序列化對應出錯。
爲了保持兼容性, field number 定義好之後是不能修改的。增加新的 field 只能用新的 number 數字;隨便更動其他已存在的 field number 都會造成很大的問題。詳細可參考 Protobuf - 序列化反序列化詳解,看完解析流程就可以很清楚知道為什麼不行這樣做了。
接來是一些小細節補充 :
int32 >> int64(思考一下 Varints 算法,不難發現正數的前提下 int32 和 int64 天然兼容!這樣換沒什麼問題)uint32 >> uint64(無符號數,表示一定是正數)sint32 >> sint64(有符號數,特別表示會有負數)以上升版都是兼容的,不會因是舊版本二進制資料,使用新版本二進制解碼,而造成損壞。
Protobuf schema 中的 label, repeated 可以更改成 optional ,還是可以解析成功,只是它就會只會保留最後一個值,其餘丟棄。