
Protobuf - Encoding 結構
隨者網路傳輸、頻寬與硬體的設備的改善和增強,能傳遞資料量也越來越大、越來越複雜,這時我們也不再只是追求能夠將資料傳遞完成,而是更加要求短時內傳遞大量的資料,故勢必會需要強化序列化和壓縮的技術。這篇會介紹 Protobuf 編碼後的 byte array 結構,以及會這樣設計的思路,當有了基本的認識後,就會明白 Protobuf 為何它可以比 JSON、XML 傳輸效率更高,更能壓縮資料,實現高效率。
前言
來看看 -128 不同的表示型態 :
以 2’s Complemen 「數字的編碼」表示 :
-128 => 128 二進制 `10000000` => Complemen 得 `01111111` => +1 `10000000 ` => 此值可以儲存在 1 byte 中以 UTF-8「文字的編碼」表示 :
'-'、'1'、'2','8' (ASCII 字符) = 45、49、50、56 (十進制) 0x2d、0x31、0x32、0x38 (十六進制) = 每個字母至少需要 1 byte,故共 4 bytes
由上述的舉例,不難發現本質上文字編碼就會需要比較多的 bytes 來儲存,而 XML 或 JSON 就是屬於全部轉成「文字編碼」。為了避免全部都換成「文字編碼」造成冗余, Protobuf 決定在描述檔內加上資料的類型 type ,來針對個別資料類型做特定的壓縮算法,回到二進制來優化。
對於 JSON、XML 資料傳輸時,會保留資料的結構化資訊,舉個 JSON 例子 :
{
"author": {
"name": "henry",
"age": 27,
"interests": ["diving"]
}
}
其結構化資訊就是指 : {}、key name、:、,、]。故人們一樣開始思考: 是否真的需要保留這麼多的結構化訊息? 應該可以再簡化一些吧? 對於資料傳輸交換,本來發送方和接收方就會密切合作,對資料的結構都會有所共識,故真的有需要在每次資料傳輸時,每筆資料都要附上這麼多結構化資訊嗎? 應該是可以簡化一些的。
Protobuf 最終的結論,是決定刪除許多傳送資料時會附上的結構化資訊,因此可以更加壓縮資料。而發送方和接收方,維護一份共同的<結構聲明檔>,雙方都參考此<結構聲明檔>來序列化反序列化資料,而這個<結構聲明檔>就是 .proto。
由於 Protobuf 是二進位資料格式,數
據本身不具有可讀性,且雙方必須有共同的 .proto檔案才能有效編碼和解碼,故一定程度上保證了其安全性。
也由於雙方必須有共同的 .proto檔案才能有效編碼和解碼,故也稱 protobuf 是缺乏自描述性的。
Encoding 結構
首先定義一個 .proto
syntax = "proto3";
message Author {
optional string name = 1;
optional int32 age = 2;
repeated string interests = 3;
}
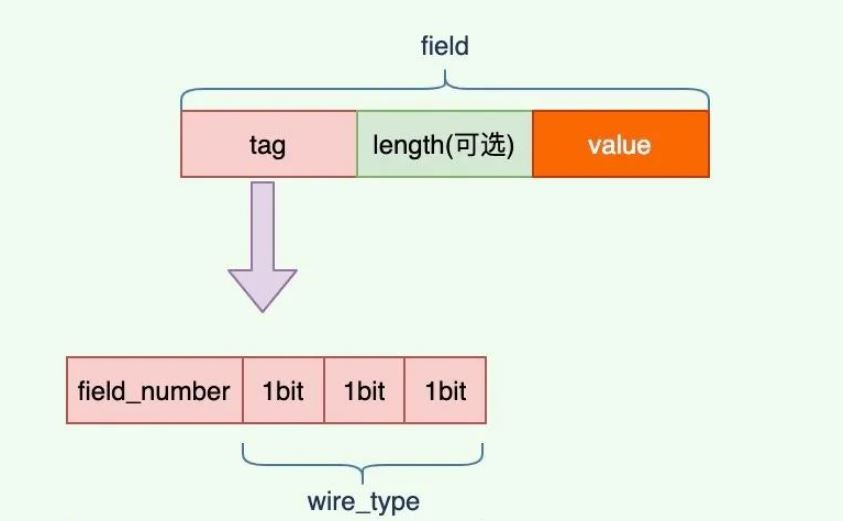
當一個資料實例,被 Protobuf Author Message 編碼後,其每個 field 會被表示成的結構,粗略表示大概會像這樣: (field number, type, payload),會使用 payload 這個名詞,是因為這部分的內容物,可能是 :
- 全都為被壓縮的值
- 包含 length 和其被壓縮的值
由於都不太算是真的資料的值,所以就不用 Value 來形容,換個字眼使用 payload 來說明避免混淆。更進一步說明, Protobuf 編碼後所得到的結構,會是如下圖:

承上結構,會發現 Protobuf 已經做了一些事情,分別是:
Tag 是什麼呢 ?
在 Protobuf 中, Tag 是 (field number, WireType) 歸類為一組的名稱,整體才代表 field 的唯一標示,簡單說就是 Tag = field number + WireType。
Tag = field number + WireType,突然多出個 WireType,和 type 有什麼不一樣呢?
Protobuf 編碼後 Type 會轉換成 WireType 。因為 .proto 檔中有很多 type 種類選,但實際上可以簡單歸類分成幾組,減少數量,分組後就稱為 WireType。
綜合以上,這種結構被稱為 Tag-Length-Value,簡稱(TLV),接下來說明 「WireType」 和 「Tag-Length-Value」。
WireType
Protobuf 對 Type 做了專門的分類和編碼,把 string、int64…等等在 .proto 內各式不同的 type,對應成一個 Protobuf 中的 enum,稱為 WireType,故每個 WireType 有自己的 field number。「不同的 WireType 對應的 payload 格式不同」,可以通過序列化的 WireType 的值,知道後續的 data 儲存方式。
WireType 的作用是告訴解析器 payload 的格式,表示這個編碼中,下一個 byte 到底是代表 length 還是 value。
| WireType | 定義 | 編碼方式 | Used For |
|---|---|---|---|
| 0 | Varint | 值被編碼成可變長度的 byte array | int32, int64, uint32, uint64, sint32, sint64, bool, enum |
| 1 | Fixed64 | 固定 64 位元的二進制 byte array | fixed64, sfixed64, double |
| 2 | Length-delimited | byte array 前綴加上其長度,用來序列化 string、嵌套的 message 或 byte array | string, bytes, embedded messages, packed repeated fields |
| 3 | Start group | deprecated | |
| 4 | End group | deprecated | |
| 5 | Fixed32 | 固定 32 位元的二進制 byte array | fixed32, sfixed32, float |
對於不同 WireType ,其 payload 格式也不一樣,故根據 WireType 可以把 Protobuf 的 payload 格式分成以下幾類:
- Varint/Zigzag
(WireType = 0)- Value
(WireType = 1),固定 8 個 bytes(WireType = 5),固定 4 個 bytes
以上為 T-V 格式。
- Length + Value
(WireType = 2),會需要 Length 來記錄 Value 的 bytes 長度,但 Value 也需要區分幾種類型:
- String 類型,使用 UTF8 編碼
- 嵌套另一個 Protobuf Message 類型
- 有 repeat label
以上是 T-L-V 格式。無論如何,基本結構如下圖:
通過不同的 WireType 會使用不同的 payload 格式,來節省 field 的空間。基本上 field 根據 payload 就分成兩種形式:
- T-V (
WireType = 0, 1, 5) - T-L-V (
WireType = 2)
如果知道了 field number,那把它對應到 .proto 文件後就能知道 type 了,為什麼還要把 type 資訊轉成 wireType 編碼到 byte array 內呢 ?
主要因為擴展性! Protobuf 是可以自由移除掉 optional field 而不會影響新舊格式資料的序列化/反序列化,那是如何實現這一點呢? 就是因為有把 type 資訊編碼到 byte array 內。
試想當我們移除了一個 optional field,但有一個舊格式的序列化資料,要用新的格式來反序列化,如果全部資訊都參考 .proto,那就完全不知道 payload 的格式到底是 T-L-V 還是 T-V ,因為新的 .proto 已經把 field 刪掉了,完全找不到訊息。
特別注意 Protobuf 編碼後所有 T-[L]-V 都是緊密接續在一起的,如果分不出來 是 T-L-V 還是 T-V ,那下一個 field 的 bytes 就會可能拿錯,導致全部解析失敗。
那接下來說一下剛剛一直提到 T-[L]-V 儲存格式吧~
Tag-Length-Value (簡稱 T-L-V)
Tag
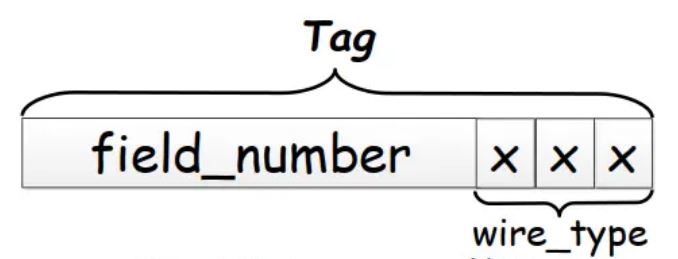
其中 T 就是代表 Tag , 由 field number + WireType 組成, Tag 的最低三位表示 WireType。配合 WireType 章節中的表格,也可以知道為什麼這裡 Tag 的圖中,WireType 只需要用 3 個 bit,因為 WireType 目前只有 6 種,所以使用 3 個 bit 完全夠用。
所有的 Tag 內 field number 的都有 Varint 壓縮,展示如下圖:
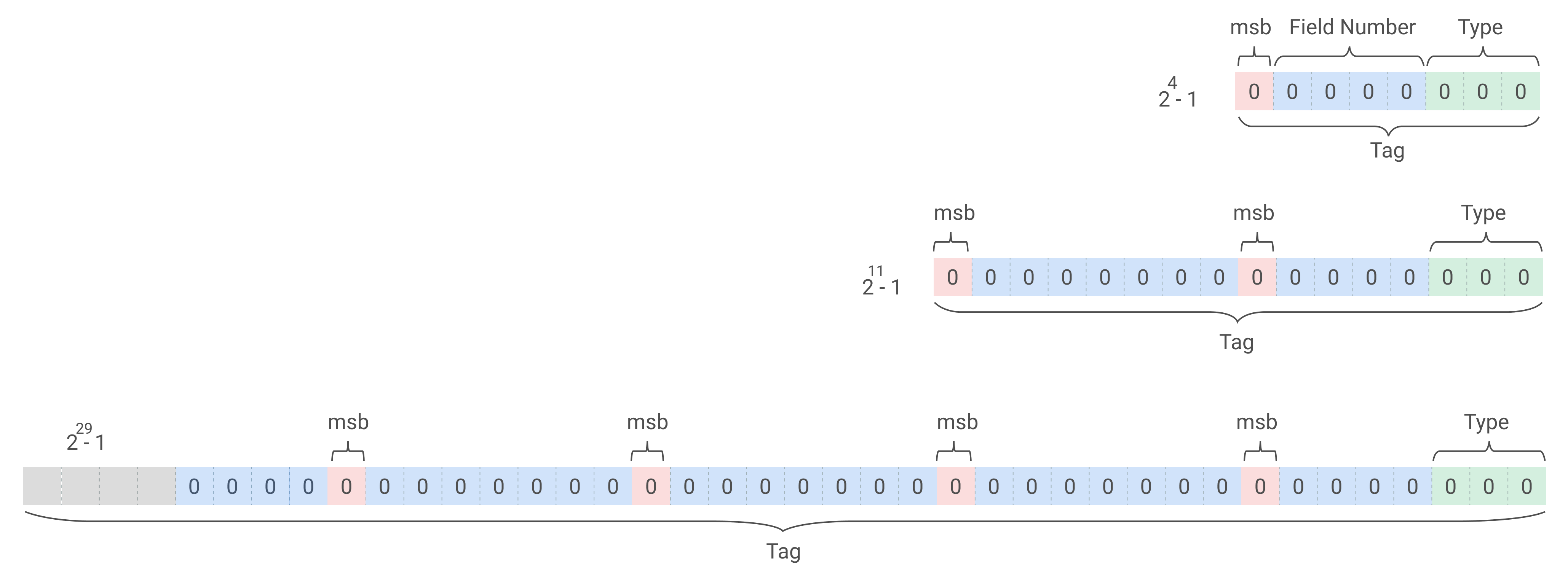
故 [1, 15] 編號範圍內的,只需要用一個 byte 編碼表示,所以將 15 以內的編號,留給頻繁出現的資料,可以進一步節省空間。Tag 值計算公式如下,代表 Tag 到底佔了幾個 bytes :
Tag = (field number << 3) | WireType number
Length
而 L 就是指 Length ,是可有可無的,同時也有使用 varint 壓縮。只有 WireType = 2 時,才需要 Length。 而 Length 是可選的原因,是因為看 Tag 內的 WireType 訊息,就能知道 value 的編碼是甚麼。像是:
WireType = 0時, 是使用 Varint 編碼,這種編碼方式是自帶 length 的資訊的,故不需要再另外多儲存一個 Length ,可以更加節省空間。WireType = 1, 5,後面會使用固定長度的 byte array ,故不需要再另外多儲存一個 Length,也可以節省空間。
Value
V 就是指 Value,這部分等到序列化-反序列化章節時,在詳細介紹。基本上對於數值部分,也是有使用 varint 來壓縮,甚至針對負數,會特別使用 zigzag + varint 來優化,可參考 Varint & Zigzag Encoding。
補充整理
從上述的介紹,應該有發現 .proto 中定義的 Message Author 內所有 key名稱,也就是 name、age、interests,都不在 T-L-V 內,protobuf 其實根本沒有把這些訊息編碼進去 byte array 內,而是僅僅使用了 field number + WireType來當主要參考,故序列化-反序列化時都需要參考 .proto 檔案。
這一點相比我們熟悉的 json 很不一樣,因為 json 是會把 key 訊息傳送出去的。 所以對於 protobuf 來說沒有 .proto 文件是無法序列化-反序列化成功的。但省略 key名稱,加上緊湊,除了壓縮儲存空間,還可以讓編碼解碼速度更快。
另外從圖中也可發現這樣一堆 T-L-V 緊湊串在一起的結構,這種存儲方式還有個優點,就是不需要分隔符就能分隔開字段,減少了分隔符的使用。
綜合上述,把 protobuf 有用到的壓縮方式統整一下 :
- 不使用 txt 系統編碼而使用 byte 來編碼
- protobuf 編碼過的資料沒有 key 資訊
- T-L-V 緊湊串在一起,不需要分隔符
- 可選的 length 有機會減少 byte
- 使用 varint/zigzag 來壓縮數值的資料