
淺談 Concurrency 與 Asynchronous
前面基本介紹了 Process 、 Thread,而在現實世界中 Process 、 Thread 的任務是更加複雜的,都會是需要「多執行緒(Multithreading)」和「多進程(Multiprocessing)」來協調達成的,再來是要如何更高效更多工的處理多個不同的工作,變成是經常需要思考的問題,這時 :
- 非同步(Asynchronous) : 執行 Non-blocking 操作,允許程式在等待某些操作完成時可執行其他任務,之後可再回頭處理之前等待操作剩下的部分
- 併發(Concurrency) : 是系統能夠在一段時間內處理多個任務,這些任務可能交錯執行,不一定要同時發生
兩個關鍵字會經常一起出現,因為 Concurrency + Asynchronous 是許多高效能應用的關鍵,接下來就簡單談一下吧!另外可以稍微注意一下其他相關名詞的中文英文對照。
雖然 Concurrency 與 Asynchronous 是兩個常同時一起提起的詞,但又很難說他們真的很相關,頗有一種相關係數是 0.38的怪異…,到底算低度相關還是中相關有各個看法 ; 同理看來 Parallelism 和 Synchronous 一起看也是相當微妙呢 ! 但我解釋脈絡上還是會把它們放在一起同時說明,以下就來談一下吧 :
Concurrency - 常見翻譯 : 併發、並發
首先 Concurrency 是一個比較廣泛的概念,它單純代表計算機能夠同時執行多項任務,至於怎麼做到的,可以用多種形式 :
Concurrency 是指在同一時間範圍內處理多個任務。另外注意這些任務不一定要真正同時執行,而是可以交錯進行的。
實現 Concurrency 的技術中最容易理解的是「時間分片輪轉調度(Time-Slicing Round-Robin Scheduling)」,簡單說就是在操作系統的管理下所有正在運行的任務都 :
- 輪流使用 CPU
- 每個任務允許佔用 CPU 的時間非常短 (比如 10 毫秒)
由於切換得很快,故用戶可能根本感覺不出來 CPU 是在輪流爲多個任務服務,就好像所有的任務都在不間斷地運行一樣,但實際上在任何一個時間內有僅有一個任務佔有 CPU。以上的解釋比較是屬於從 「CPU 運行的角度」來說明,若從 「Thread 的角度」去談, Multi-Thread 間彼此需要協調等待,交出 CPU 執行時間片的使用權,這也是一種 Concurrency 併發,以上的事情也被稱為process/thread 的上下文切換。
那再多核 CPU 情況下,如果任務數小於 CPU 數,且不同任務可以分配給不同的 CPU 來運行,讓多個任務達成「真正同時運行」,這就是所謂的 Parallelism。
Parallelism - 常見翻譯 : 平行、併行
Parallelism 定義是要多個 Process/Thread 同時平行處理多個任務,能夠利用「多核心 CPU」的數量特性,適合用在圖像處理、算法處理、機器學習等需大量計算,提高效率
Concurrency 主要關注於任務的管理和調度,要在一時間段內處理多個任務,不論是通過時間片輪轉在單核處理器上切換進行,還是在多核處理器上水平並行。 Concurrency 和 Parallelism 會同時出現比較像是想對比 「交錯執行」 與 「同時進行」的概念。
Parallelism 定義是要平行同時處理多個任務的 ; 而 Concurrency 的關鍵是有處理多個任務的能力,不一定要同時,所以可以說 Parallelism 是 Concurrency 的 subset,而 Parallelism 是提高 Concurrency 的一種實現方式。
如果真的要說 Parallelism 的反意詞,使用 Sequential Processing 或 Serial Processing 會是最準確的。但雖然是這樣說,偶爾還是會有人用 Concurrency 來當 Parallelism 的反意形容 … 溝通上要注意一下!
再講 Asynchronous 之前我們先講簡單的 synchronous , 由於 「synchronous(同步)」代表需要等到前一個任務執行完畢之後,才能進行下一個任務,因此在 「synchronous 中完全沒有 Concurrency 或 Parallelism 的概念。
Asynchronous 非同步/異步
任務可以「不阻塞」當前執行流程,允許程式繼續執行其他工作,並在未來某個時間點返回來繼續進行剩下的任務部分。
一般來說 Asynchronous 會使用在例如 I/O 等相對「慢」的操作任務上(與 CPU 和 RAM 速度相比的慢),實際舉例的話如下 :
網絡資料的收發、遠端 API 操作
任務執行時間主要消耗在「等待」回應上
像磁盤文件讀寫、資料庫操作
任務執行時間主要消耗「I/O 操作」上,因此也稱為「I/O bound」
以磁盤文件讀取寫入的 I/O 操作爲例,實際上是 code 通過系統調用的方式,向操作系統發出讀寫請求。以 read 函數爲例在 Synchronous 調用方式下,文件在讀取完之前 main thread 是無法繼續向前進的,只有當 read 函數返回後才可以繼續往後
由於 Synchronous 也是按照順序調用執行,故也稱為 Sequential
若 read 函數以 Asynchronous 調用的話,那即使文件還沒有完全讀取完成,read 函數也可以執行接下來的 code,這就是異步的高效之處。

Asynchronous 主要關注於提高程式在「等待期間」的效率,允許程式在等待一個操作完成的同時,繼續執行其他任務,從而避免阻塞。
與此相對的,若大部分執行時間,都是實際運算工作而不是等待回應,因為計算機中的工作是由 CPU 完成的,因此可將這些問題稱為「CPU bound」。
Asynchronous 的實現方式: Notify / Callback
有個典型實現 Asynchronous 的方式則是透過「 multi-thread 」,以常見的 Web 服務來舉例, 當 Web Server 接收到用戶請求,後續操作經常會做一些資料庫查詢之類的事情,故一般來說 Web Server 服務通常有兩個典型的 Thread :
- Main-Thread
- DB-Thread
假定處理一次用戶請求,需要經過步驟 A、B、C,然後有「資料庫查詢請求」的操作,再來查詢請求完成後還要經過步驟 D、E、F,其中只有「資料庫查詢請求」這一步有涉及到 I/O、網絡通訊等等「慢操作」,如下所示:
mainThread() {
A;
B;
C;
資料庫查詢請求; // 慢操作
D;
E;
F;
}
在最典型的 Synchronous 設計下,Main-Thread 在發出資料庫查詢請求後,就會「阻塞」等待直到資料庫查詢完畢並接受到回應資料,之後 D、E、F 才可以繼續運行,但顯然可以發現這並不夠高效,因為 Main-Thread 會有運行空隙,利用效率時還可以在增進的,如下圖是 Synchronous 示意 :
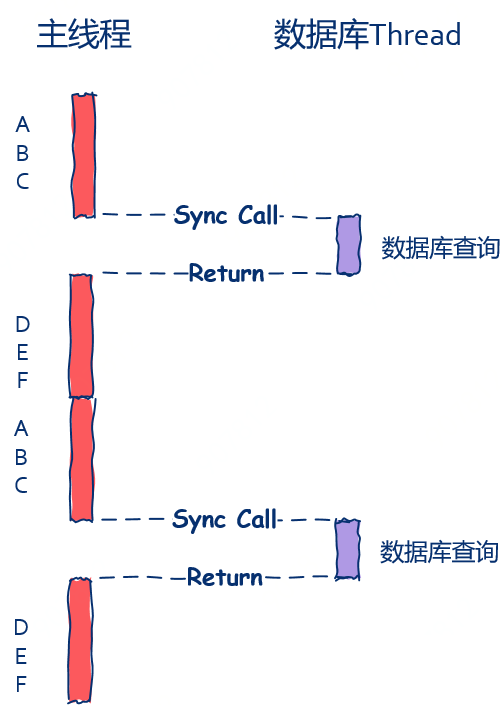
這時候 Asynchronous 就是蠻好的優化方式,在 Asynchronous 實現下, Main-Thread 不用去等待資料庫是否查詢完成,而是發送完資料庫讀寫請求後直接處理下一個請求。
在 Synchronous 同步調用下, Main-Thread 會被阻塞,等到被調函數執行完後很自然的就是繼續執行 ; 相比之下 Asynchronous 非同步調用下, Main-Thread 可以直接就去處理下個請求了。
那麼接下來思考一下,在 Asynchronous 調用下「調用方」怎知道「被調函數」是否執行完成呢?
承上面範例來說, Main-Thread 在完成 A、B、C、資料庫查詢後,直接處理接下來的請求了,那麼上一個請求中剩下的 D、E、F 怎麼辦呢?這就是本節要說的 Notify & callback ,接下來那我們來討論一下處理 D、E、F 的需求情況,這可分爲了兩種需求模式:
- 調用方不用關心執行結果
- 調用方必需要知道執行結果
回調函數 (callback function)
在調用方不關心資料庫操作結果的情況下,我們可以簡單使用「回調 (callback)」機制來處理後續的 D、E、F 請求。例如我們可以將處理 D、E、F 這幾個步驟封裝到一個函數中,假定將該函數命名爲 AfterDBQuery :
void AfterDBQuery () {
D;
E;
F;
}
主線程在發送資料庫查詢請求的同時,將該 AfterDBQuery 函數一併當做參數傳遞過去給 DB-Thread :
DBQuery(request, AfterDBQuery);
DB-Thread 處理完查詢請求後,DB-Thread 可以就直接調用 AfterDBQuery 來執行操作,而這個函數就是所謂的「回調函數」。
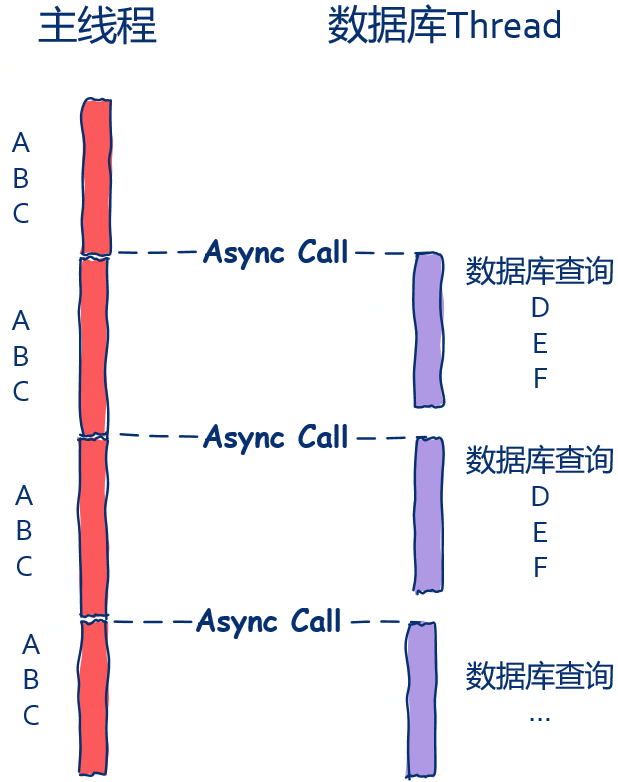
DB-Thread 需要做的僅僅就是查詢資料、然後調用 callback function ,至於這個 callback function 做了些什麼 DB-Thread 不用關心也不應該關心,因為只有使用方知道資料查詢完後該做些什麼,故從系統設計上來講,接下來要做什麼這件事情,不應該是 DB-Thread 來定義的,因此 DB-Thread 只要簡單的執行傳入的 callback function 就可以了,而不是自己去詳細定義要做什麼。
通知機制(Notify)
在 Main-Thread 需要知道資料庫操作結果才能進行下一步的情況下,需要使用「通知機制(Notify)」機制, DB-Thread 需要將查詢結果利用通知機制發送給 Main-Thread ,而 Main-Thread 在接收到消息後回頭繼續處理上一個請求的後半部分,示意圖就像這樣 :
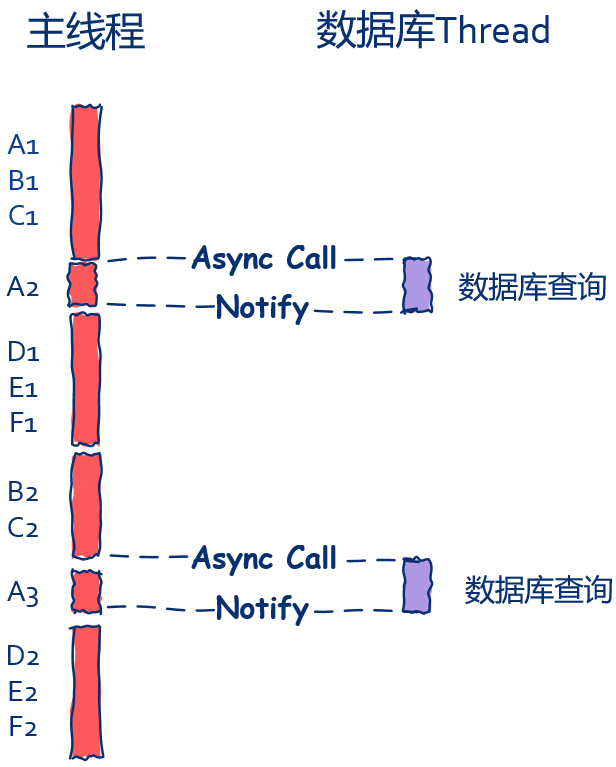
從這裏我們可以看到,ABCDEF 幾個步驟全部都由 Main-Thread 處理
雖然上面的 Asynchronous 舉例都是多執行緒的,但Asynchronous 也可以單執行緒執行,例如 Python 的 asyncio 就是用一個 Main-Thread 單執行緒達成非同步機制