
GCP - Bigquery 概述 I - 架構
BigQuery 是 Google 提供的一個無伺服器資料倉儲 (Serverless Data Warehouse),其支持 ANSI SQL 來搜尋資料,所以只要會 SQL 語法就可以立即開始使用,且可高效率分析 TB、PB 等級的資料,故 Bigquery 也是企業級雲端大數據資料分析平台。對應到其他的雲端服務是 :
- Amazon Web Services (AWS) : Athena、Redshift Spectrum、Redshift
- Microsoft Azure : Azure Synapse Analytics
Google 在非常早期的時候,就有類似 BigQuery 其的服務就存在了,是自 2006 年以來一直在內部使用的 Dremel,後來隨著 GCP 雲端平台的產生,並於 2011 年以 BigQuery 為名被正式推出。目前是 GCP 分析資料的主力產品, Google 自家產品如搜尋引擎、 Gmail 等服務背後,其資料處理與分析的核心技術也和 Bigquery 息息相關。
Bigquery Architecture
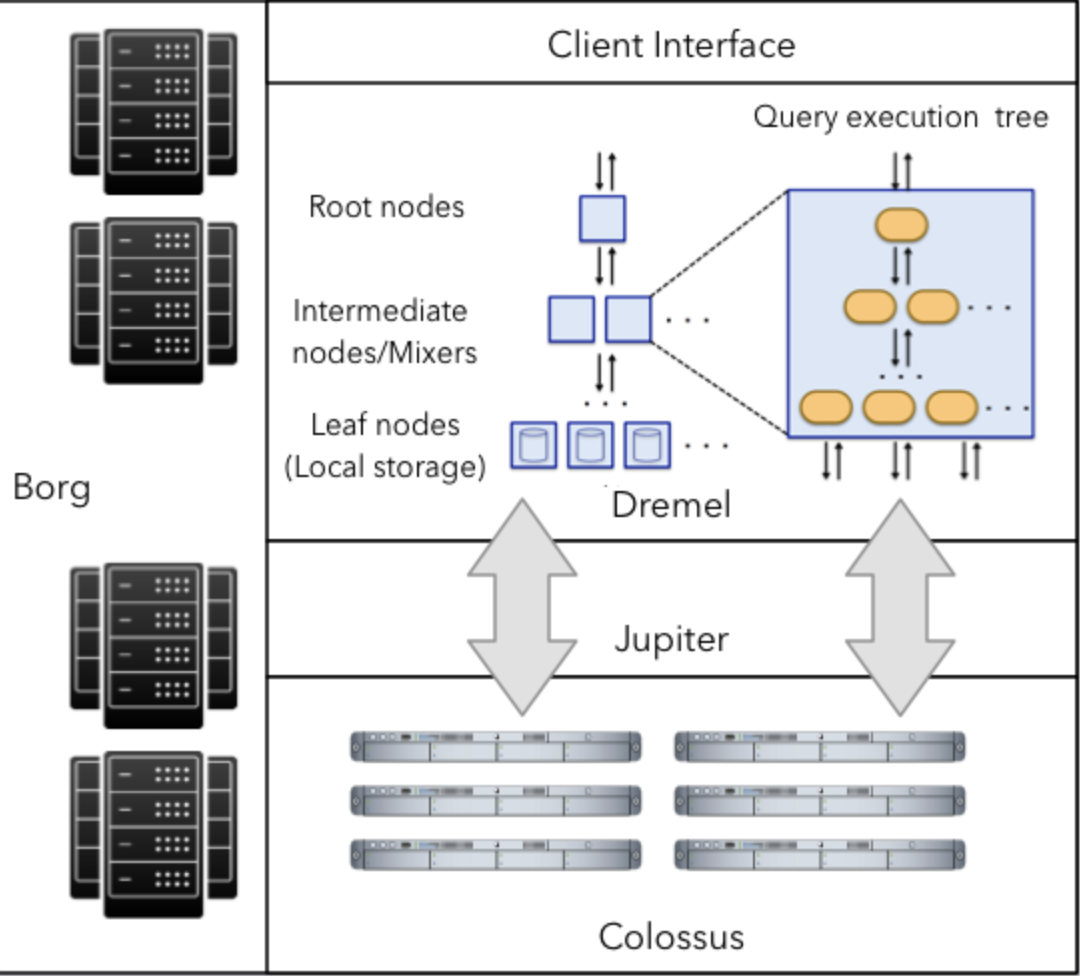
BigQuery 服務利用了許多 Google 的技術如 :
- Borg: kubernetes 前身,由數台 VM 組成的集群
- Dremel: 可平行處理查詢的執行引擎,實現了一個 multi-level serving tree
- Colossus: Google 最新一代的分散式文件系統,GFS 的繼任者
- Capacitor: Column Oriented 儲存格式
- Jupiter: Google 的 Petabit 等級的高速網路,用於儲存和分析兩者溝通
BigQuery 架構很重要的是把 「compute」 和 「storage」 分離,這可以讓 BigQuery 根據需求獨立 scale up/down 其 storage 或 compute 資源,但也由於計算和存儲間的分離,故需要一個超高速網路讓其可以在幾秒鐘內將數 TB 及資料的傳輸於其間,而 Jupiter 是能夠提供 1 PB/秒 的頻寬的網路服務。
Compute
首先介紹計算資源。當要在 BigQuery 內查詢資料時可能是利用 BigQuery Client 下一個 SQL 語法,接著 Client 會和 Dremel engine 互動, Dremel engine 作為 root server 會把查詢重寫拆成小部分,然後 parallel 並行分配給其下的 Dremel jobs,而 Borg 就會為這些多個 Dremel jobs 分配其計算容量。
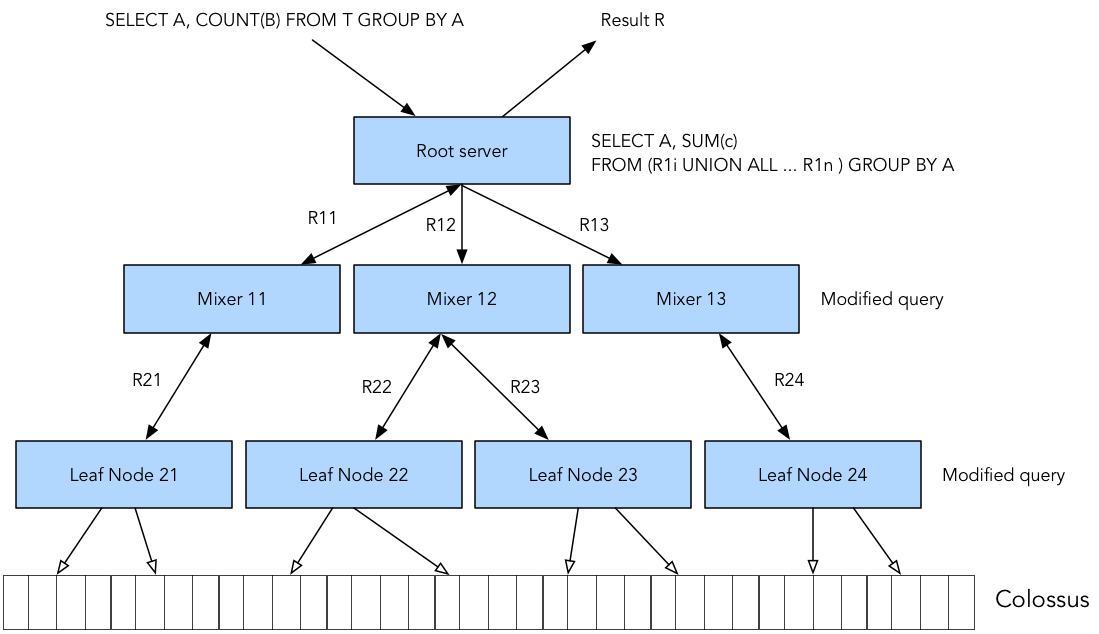
Dremel 會從 Colossus 儲存系統讀取相關資料,其因是完全在記憶體中執行 query ,且是使用 Jupiter 高速網路確保資料從 Colossus 讀取到 Dremel 內,故每個 Dremel Jobs 能以極快速度達成分析。最後所有 Dremel Jobs 做完分析之後,會把結果回傳給 Root ,然後 Root 會把每個運算分析的結果,整個收集合併起來,才回傳給 Client。
執行過程中需要的計算資源,都不需要自己控制分配,都是由 GCP 完全代管的,而底層是 BigQuery 利用 Borg 進行計算分配和處理容錯
Storage
BigQuery 是把資料存儲在分散式文件系統 Colossus 內的,也是由 Google 提供完全代管,存儲容量大小的調整也是自動的,然後資料會在其中自動壓縮、encrypted ; 再來為了實現高可用,還會跨 zone 的 replica 來備份資料,進一步若在 BigQuery Dataset 內設定 Multi-Region 則還會跨 region 備份,可用於災難復原使 BigQuery 具有更高可用性。
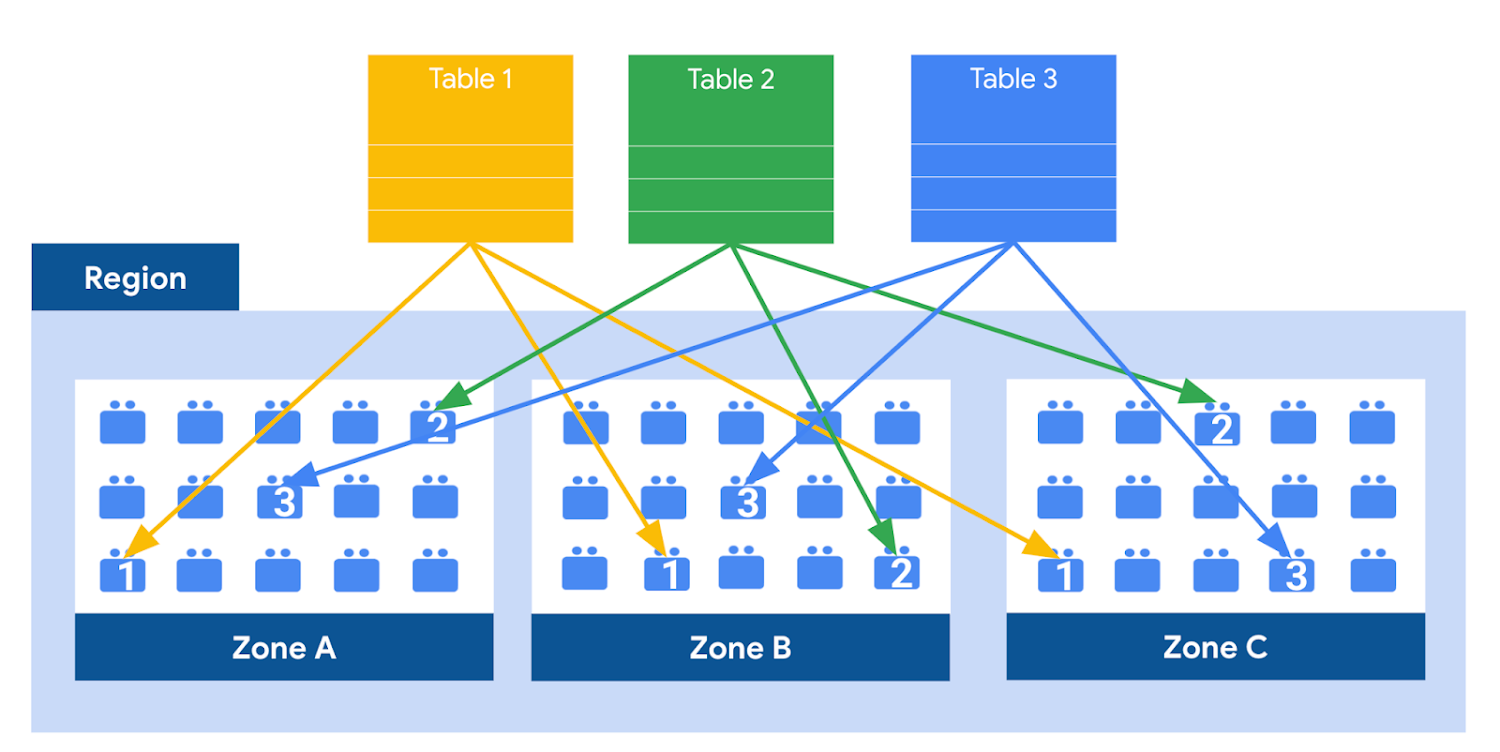
BigQuery 是屬於 Column-Oriented databases ,更進一步說明: BigQuery 的儲存是一種稱為 Capacitor 的格式,壓縮方式類似如下:
c1 c2 c3 c1 c2 c3
-------- ----------------------
a 2 z ====> (3, a) (2, 2) (1, z)
a 2 x (4, b) (3, 1) (3, x)
a 1 x (2, 3) (2, y)
b 1 x (1, z)
b 1 y
b 3 y
b 3 z
在 BigQuery 內 Table 的每個 Column 都會被單獨儲存,並以 Capacitor 格式寫入 Colossus 內,當被發送到 Colossus 進行永久儲存時,所有內容都會被加密並會開始備份冗余。
BigQuery 也可以串接使用外部資料源例如 Bigtable、Cloud Storage 和 Google Drive 等等,這時在執行 query 時, BigQuery 會將外部資料動態載入 Dremel 的 in-memory 來進行運算,此時外部資料不會被 BigQuery 儲存。
一般來說 BigQuery 使用外部資料源運行的查詢速度,會比資料儲存在 BigQuery 內部表運行的速度還要「慢」。如果對性能有要求,那麼在運行查詢之前建議將資料導入先 BigQuery 內
Resource hierarchy
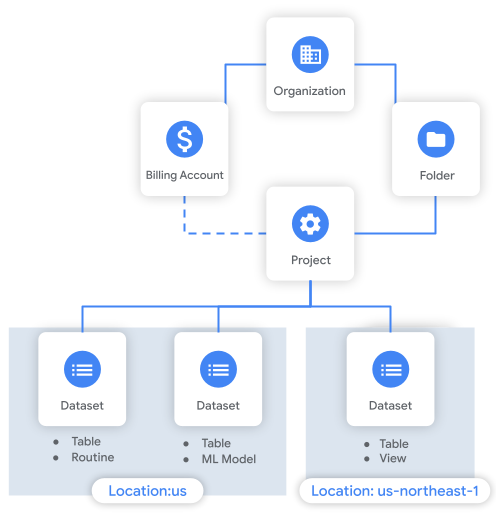
BigQuery 也有所謂的 Resource hierarchy ,此用來管理 BigQuery 的 permissions、quotas、billing 等等,比較特別的是還多了個名為 Dataset 的分組。
Dataset
Dataset 是用來管理和控制 BigQuery 資源,比喻上可以想成是一個資料庫。為什麼可以這樣想呢?因為 BigQuery 資源如 tables、views、functions、procedures 都是建立在 DataSet 中,和傳統資料庫概念上很相像呢。
要建立 Dataset 時需指定 Location ,且創建之後無法更改,再加上當我們要創建 table 時, table 也是會歸屬在 Dataset 之下的,故需要思考一下 location requirement。然後 tables 透過相同的 Dataset 名稱管理在一起,在 BigQuery 查詢表格操作上,需要加上 Dataset 名稱來識別資源位置,格式為: projectname.datasetname。
Project
每個 Dataset 都會關聯一個 Project,而 Project 內可以有多個不同 location 的 Dataset , UI 顯示上 Explorer Panel 內的 Project、Dataset、資料表會呈階層式排列。
BigQuery 的每個執行動作均稱為 Job,而 Job 本身會關聯到一個 Project ,主要是因為 quotas 計費是以 Project 為單位。雖然 Job 本身是連結到一個 Project,但是 Job 在執行動作時的資料 table 來源,可以是來自多個不同 Project 的 Datasets。
tables、views、functions、procedures 都是建立在 DataSet 中。但 Connections 和 jobs 是例外,這兩個與專案相關聯而不是 DataSet
Organization / Folder
Organization 概念上經常表示一家公司 Company,雖然不需要 Organization 也可使用 BigQuery,但還是建議創建 Org 用來集中控制 BigQuery 資源 ; 而 Folder 概念上經常表示公司的部門 Departments,然後 Folder 可以有多個層次,且其會自動繼承其 parent folder。
如果希望 organization 中的 Departments 使用不同的 Billing accounts,那建議為每個 Departments 開不同 Project ,然後在 organization level 創建 Billing account ,再將它與 Project 關聯。
Practice
假如需要負責優化 GCP Resource 使用情況,具體來說需要調查 resource consumption charges(資源使用費用),分析並呈現調查結果,Google 推薦應該怎麼做?
答案是:
Attach labels to resources to reflect the owner and purpose. Export Cloud Billing data into BigQuery, and analyze it with Data Studio.
- Label 是 GCP 最推薦的管理資源方式。可以將 Label 附加到資源上就可以在 Cloud Billing 報告中清晰地看到各個資源的費用歸屬。
- 可以將 Cloud Billing 導出到 BigQuery 可以做分析,並使用 Data Studio 創建直觀的報告,這種方式自動化程度高,分析過程簡單高效。
Label、BigQuery、Data Studio 的結合,可以自動化費用分析並生成可視化報告,這是 GCP 推從的「費用分析」解決方案。
特別注意在 GCP 中 Tag 通常是指 VM 的 Network Tag,和資源管理沒有任何關係。