
GCP - Bigtable 概述 I - 架構
Bigtable 並不是傳統 RDB 關係型資料庫,而是 GCP 提供的企業級 NoSQL Database,是一個支持大數據應用的分散式存儲系統,保證高可擴展、高可用性、高性能與高吞吐需求的服務,與現有 Apache Big Data 生態系統的開源軟體如 HBase 也有蠻好的整合。對應到其他的雲端服務是 :
- Amazon Web Services (AWS) : DynamoDB
- Microsoft Azure : Cosmos DB
Bigtable 優勢在於其強大的擴充性,效能完全和 cluster 中的 Node 數量成正比,該產品的強大性完全不用質疑,因為 Google 的很多重量級專案都有使用 Bigtable 來存儲資料例如: Youtube、Google Earth、Google 搜尋引擎、Google Map 等等,每個專案都為數十億活躍使用者提供穩定的服務。
Bigtable Architecture
下圖是一個 Single-Cluster Bigtable Instance ,接下來分別對其組件做簡單的介紹:
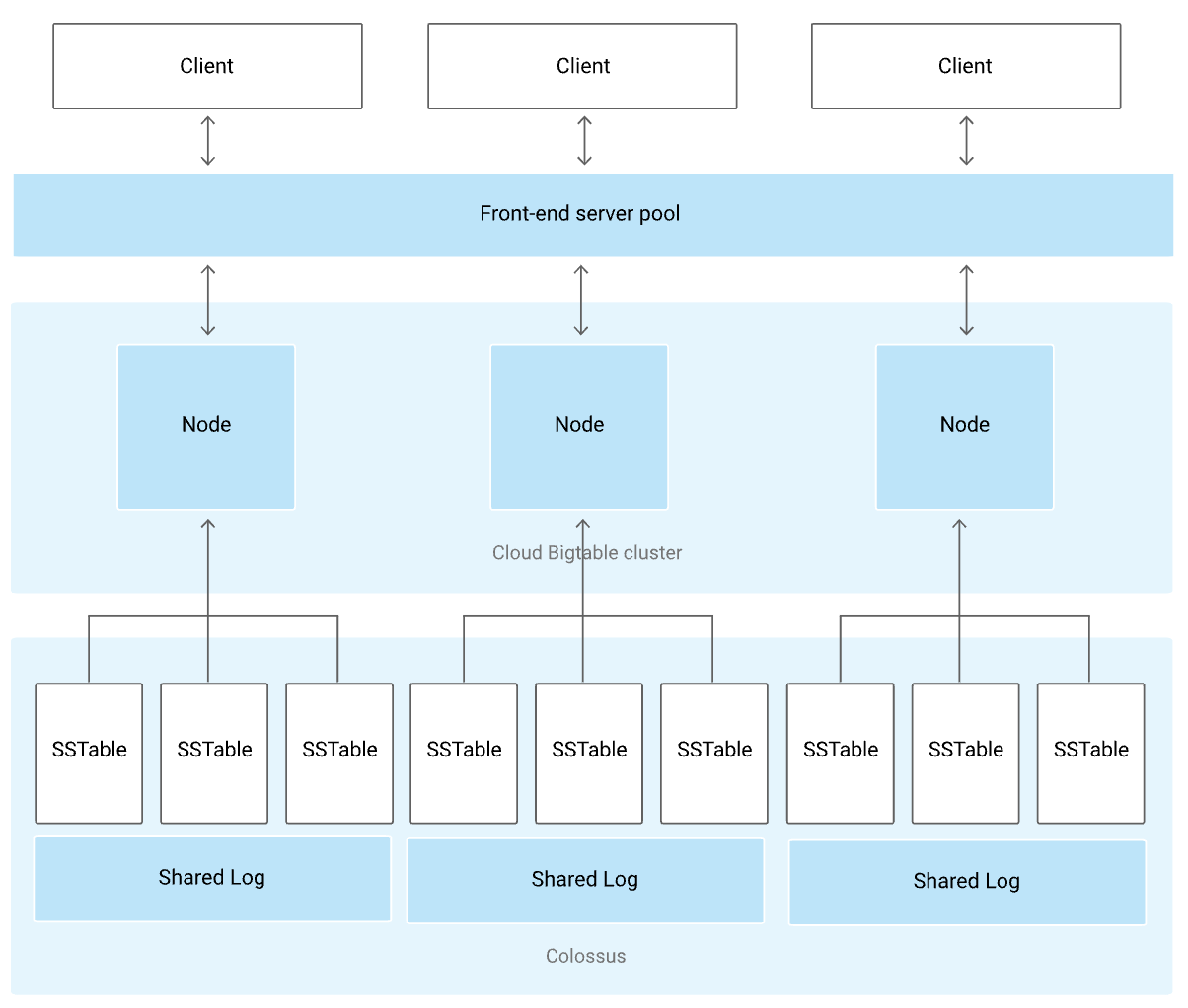
Add replication 增加成多個 Clusters 。Front-end Server Pool
Client libraries 提供連接到 Bigtable Instance 的橋樑,所有 Client 的請求都會經過 Frontend Server,然後再轉發到 Bigtable Node 。 GCP Bigtable 可以有多個 Clusters ,且可以選擇 application 要連線到哪個指定的 Cluster,故目前推測這個 Front-end Server Pool 是管理如何 route 到 Cluster 的連線。
Bigtable Cluster
每個 Bigtable Cluster 都至少有 1 個 Node ,每個 Node 都會處理 Cluster 的一部份請求,故向 Cluster 內添加更多 Nodes 之後,是可以有效處理併發請求的數量和提升 Cluster 的最大吞吐量 Throughput 。若有多 Clusters 則設定強制都要在不同 zone ,多個 Clusters 的 Bigtable Instance 會進一步提高「 Availability 可用性 」和「 Durability 耐用性」。
- Single-Cluster Bigtable Instance 提供 strong consistency
- 而預設 Multi-Cluster Bigtable Instance 提供 eventual consistency。
看了一些相關的論文, Bigtable Cluster 設計上會有兩個重要組件:「Master Server」、「Tablet Servers」,接下來對應一下在 GCP Bigtable 的官方文件內容 :
Tablet Servers (Node)
在 GCP Bigtable 官方文件中有特別說明,對應到原始 Bigtable 論文這邊 Node 的舊稱即是 Tablet servers,而 Node 在原始論文中的功用為 :
- 管理追蹤多個 tablets
- 負責處理對 tablets 的讀寫請求和
- 若某個 Tablet 的 traffic 或 size 太高或太低,會執行 Tablet split/merge
最初 Table 資料都只有儲存在一個小 Tablet 內,隨著單一個 Tablet 內資料 size 的增長,Node 還會把大 Tablet 分裂成更多個小的 Tablets,大小控制在 100 ~ 200 MB。另外 Node 並不存儲真實資料,而是一個用來連接 Bigtable 真實儲存位置的代理,其僅只有儲存 metadata 指向真實儲存位置。由於真實資料不是儲存在 Node,故 Node 發生故障時不會丟失任何資料,且復原時使需將 metadata 訊息給到另一個 Node ,這是可以迅速進行的。
Master Server
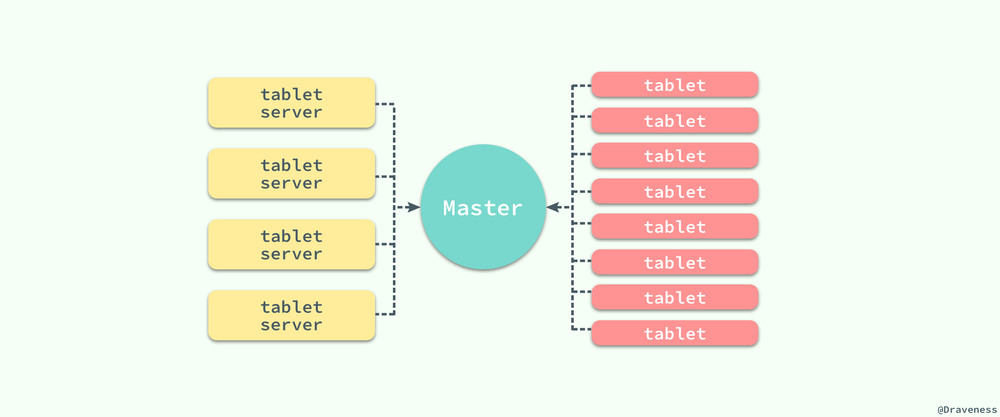
- 將 tablet 指派給 tablet server
- 偵測 tablet server 狀態,檢測新加入或者過期失效的 tablet server
- 平衡 tablet server 的負載
- 垃圾回收(GC)
- 處理 schema 變動例如 table 和 column family 的創建或刪除
Master Server 的功能看起來蠻重要的,但在 GCP Bigtable 官方文件中似乎沒特別提到,可是官方文件內有一個關於 Load balancing 的說明: 每個 Bigtable 的 zone 都有一個 「 Primary-Process 主進程」,作用是平衡 cluster 內資料,會把 tablet 分配到適當的 Node。我想這個 Primary-Process 就是擔當 Master Server 的職責吧。
比較奇怪的是, 在 GCP 官方文件 Load balancing 的說明文中說 Primary-Process 也會針對 tablets 的進行 split 與 merge ,但這應該是 Node 的職責才對…
Colossus [kəˋlɑsəs]
前面已經多次提到 Tablet ,而它是什麼呢? 為了存儲更多資料以及保持擴展性, Bigtable 會把 Table 自動 Sharded 分片成多個 rows-block 稱為 Tablets ,它是 Bigtable 中的基本單位,代表 the unit of distribution and load balancing ,概念上等價於 MongoDB 中的 chunk。
注意 Tablet 多個 t 但不是 typo 喔,「Tablet」 和 「Table」 是不一樣的東西
承前也提到 Node 並不直接存儲真實資料,那資料到底儲存在哪裡呢?怎麼被儲存的呢?簡單說明是: 真實資料儲存在 Google’s file system Colossus 中 ; 並且 Tablet 內部採用了類似 LSM(log-Structured merge) 的存儲方式,把資料的持久化用 SSTable format 儲存。
SSTable
SSTable 全稱是 Sorted Strings Table,是一不可修改的有序的 key-value 映射。每個 SSTable 由 block 組成,block 預設設為 64KB 是可配置的,在 SSTable 的尾部存儲著塊索引,用於定位 Block。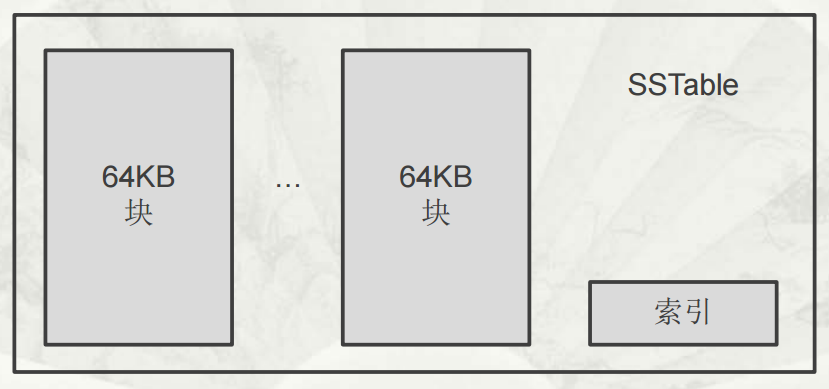
Tablet 把資料寫入到 Colossus 的流程,基本上就類似 log-Structured merge Tree 的流程 :
- 首先是先把資料寫在記憶體表 memTable 中,而不是直接寫入到 SSTable
- 當 memTable 大小達到閾值時,memtable 會被凍結然後會再創建一個新的 memtable,這時才將資料寫入到新生成的 SSTable,然後才儲存到 Colossus 內
另外由於可能發生 memTable 中的資料還沒寫入磁碟的但發生丟失的情況,所以 Bigtable 通過預寫 Log 解決了這個問題,這也是架構圖內 Shared Log 的由來,故整理可得: Tablet = 「 memTable 」 + 「 a list of SSTables 」 + 「 Logs 」
由於 Bigtable 是屬於全託管是服務,所以其實使用者也沒有機會接觸到這麼底層的儲存。從架構圖上 Colossus 、 SSTable 、Shared Log ,對於我們使用 Cloud Bigtable 基本上都是不可見的。
使用情境選擇建議
Bigtable 雖然有一些術語如 row、column、table 等等,但它並非是傳統 RDB ,其並不支持 SQL 語法查詢如: table joins、multi-row transactions 等等,反而更接近為 NoSQL。
- Firestore 是基本的 NoSQL 資料庫 ; 而 Bigtable 就是企業等級的 NoSQL 資料庫,建議資料量 1TB 以上再來考慮使用 Bigtable
- Bigtable 擅長在相對較長的時間段如數小時或數天內,處理 TB 或 PB 級數據。 因為 Bigtable 需要時間來瞭解訪問模式。如果交互持續時間很短,Bigtable 可能無法提供良好性能的方式平衡資料
- BigQuery 和 Bigtable 名稱有點相像,但是它們的用途並不一樣。BigQuery 在 Google 的定義上是 Data Warehouse,不單純只是資料儲存,還需要包含了一些快速查詢的功能在裡面
- 如果需要對 Online transaction processing (OLTP)事務處理,且支援 SQL 系統,建議使用 Cloud Spanner 或 Cloud SQL ; 如果需要在 Online analytical processing (OLAP) 互動式查詢,建議使用 BigQuery