
GCP - Bigtable 概述 II - 儲存模型
由於 Bigtable 在 Google 內部廣為使用,故有於 2006 年發表了它的論文介紹:Bigtable: A Distributed Storage System for Structured Data,然後在 2015/5 推出成為 GCP 雲端產品給大眾使用。 在 Google 官網上 Bigtable 的定義是一個 Sparsely-Populated-Table,其中 sparse 意思是如果某 Column 未在特定 Row 中使用,就不會佔用任何空間。
Bigtable 也可以輕鬆擴展到數十億 Rows 和數千個 Columns ,能夠存儲 PB 級的資料量,適合 High-Throughput 場景的服務,是個強大的服務。而個人也覺得 Bigtable 是對有使用 GCP 的人常被問有沒有使用過的一個雲端服務之一,故可以特別看一下這個服務。(第一名最常問的,我個人認為是 Bigquery)
承前篇 Bigtable Architecture 的介紹,對於部署一個 Bigtable ,其整體是稱為 Bigtable Instance 。 Instance 最前面有 Front-end Server 控制路由,再來會對應到一到多個 Clusters,而每個 Cluster 內有一到多個 Nodes,最後是儲存組件 Colossus 用來儲存中 SSTable 與 Log,整體來說簡單架構表示為:
Bigtable = 「 Front-end Server Pool 」 + 「 Cluster(s) 」 + 「 Colossus 」
Apache Hadoop 系列中 HBase 一般被認為是 Bigtable 的開源實現,甚至連 API 都可共用,適用場景也大部分重合 ; Cassandra 也是以 Bigtable 原始論文為模型實現出來的技術,不過在部分設計思路上有很大不同。
Bigtable storage model
Bigtable 對於如重啟節點、擴展、資料備份等等都是自動管理的,故對使用者來說重要的是: 需要掌握 Table 的設計,故會建議以根據經常查詢的要求來驅動 Bigtable 的 Table 設計 :

Bigtable 將資料存儲在可大規模擴展的 Table 中,每個 Bigtable 的 Table 都是一個 sorted key-value map ,且 Bigtable 將所有資料視為 byte strings,存儲邏輯可以表示為:
(row:string, column:string, time:int64) → string
Table 由 Rows 組成,而每 Row 再由多個 Cloumns 組成。雖然前面一直有提到這些在「關聯式資料庫」常常使用的名詞,但實際上 Bigtable 指的 Table 根本和關聯式資料庫的「表」沒有任何關係,承上說明也知道它的物理存儲形式其實是一個排序的 key-value 映射 ,然後 Row/Column 也和傳統 RDB 那些概念是不太一樣的,以下個別介紹:
Row
Row 通常描述單個 Entity。 Row 只有一個 value 會被編入索引 index ,這個索引 index 值就被稱為 Row-Key ,其類似於 RDB 的 primary key 主鍵,資料會按 index 順序排序儲存,故從 Bigtable 中檢索資料可以使用 Row-Key 指定特定的 Row ,這搜尋會非常高效。特別注意 Bigtable 中沒有 secondary indexes,因此 Row-Key 的設計非常重要。
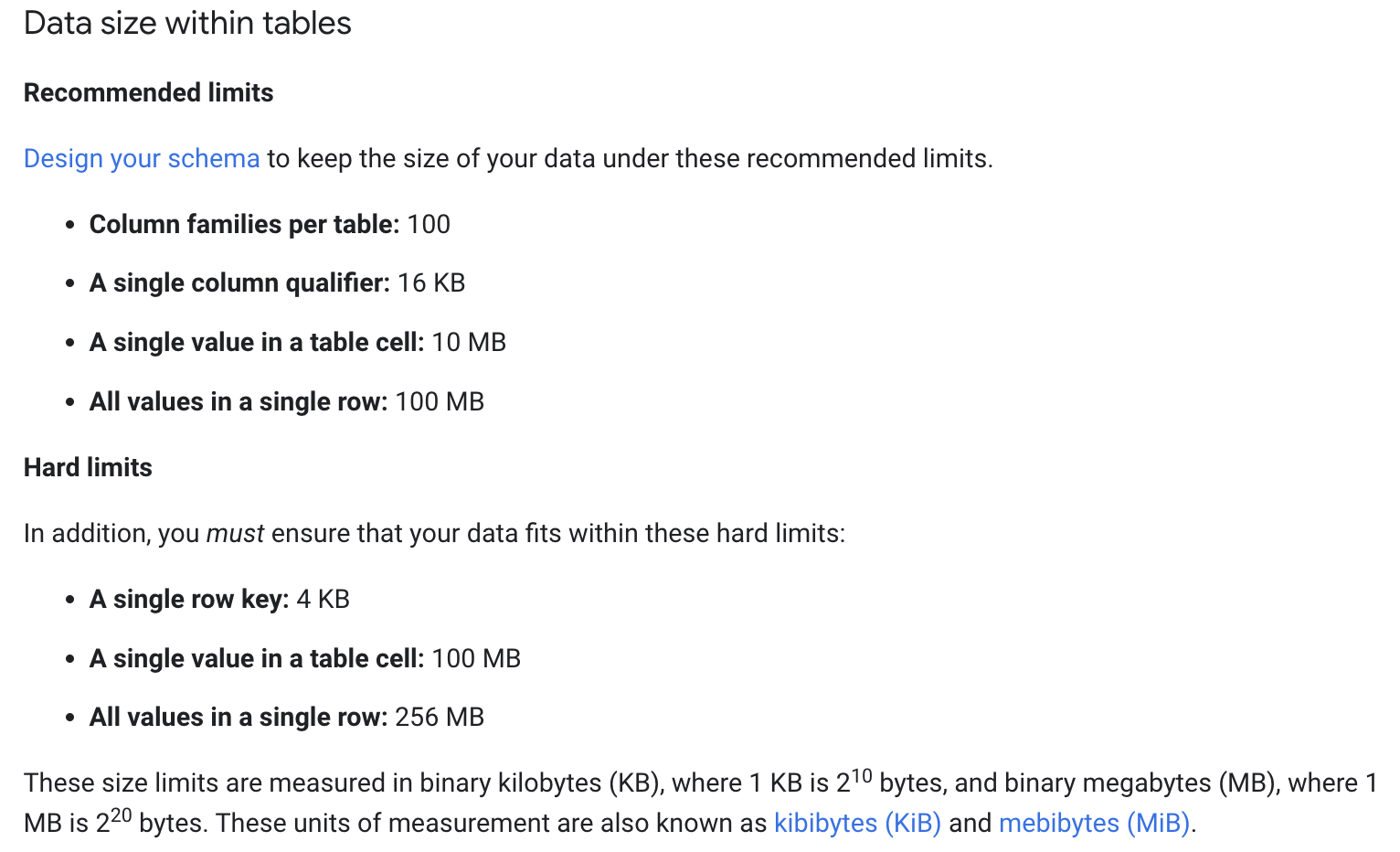
GCP Bigtable 的 Hard limits,Row-Key 不能超過 4 KB
Bigtable 通過 Row-Key 的字典順序來組織資料,Table 中的每個 Row 都可以動態分區,每個分區叫做一個 Tablet,Tablet 是資料分佈和負載均衡調整的最小單位。
注意, BigTable 支援單 Row 事務,可以對存儲在某個 Row-Key 下面的資料執行原子的 CRUD 操作,但不支援通用的跨 Row 的事務
Column
首先介紹 Column-Family ,它可整合多個 Columns 成為一群組,在定義表 Table 時 Column-Family 是一定要先定義的。再來 Column-Family 下面的 Column 可以動態添加,且無論是 Column-Family 還是單一 Column 都是按字母順序被排序存放的。
Column Key 的格式為 family:qualifier ,以 Qualifier 作為唯一標示名稱,且承上也可看出 Column-Family 會作為每個 Column-Key 的前綴。
GCP 建議 Qualifier 名稱大小不要超過 16 KB ,且在單一 Table 中 Column-Family 不要超過 100 個,但基本上單一 column 數量並沒有限制。
Column-Family 通常很少變化,其內部的 Column 一般存儲相同類型的資料,可方便對數據進行壓縮。不同的 Column-Family 可以設置不同的訪問許可權,是 Bigtable 中 Access Control 的基本單元。
Column-Family 這個方式可以很有效率的讀取一群經常被放在一起讀取的資料,實務上例如街道、地址、城市、鄉鎮、郵遞區號,這幾個欄位就是經常會被一起讀取,所以可以將這幾個 column 組成一個 Column-Family 。
Column 可以在 row 中不被使用,這也是 BigTable 被稱為 sparse 的重要原因
Cell
Cell 就是 Row 與 Column 的交集處,而且該位置會有多個版本,版本按時間戳進行索引,按 Timestamp 的降序排序(最新的資料排在最前面),每個 Cell 都有一個唯一的 Timestamp 。
GCP 建議在單一 cell 中存儲不超過 10 MB ; 在整個 Row 中存儲不超過 100 MB
Hard limits: 單一 cell 中存儲不超過 100 MB ; 在整個 Row 中存儲不超過 256 MB
為了減輕多個版本的管理產生的資料冗余,Bigtable 可以通過設置指定例如
- 只有最新的 (only new enough)
- 保留最新的 N 個版本 (only last N)
- 只保留過去 7 天寫入的版本
以上設定之後 Bigtable 就會對廢棄版本的資料,自動進行垃圾收集 Garbage collection,其是一個內建 built-in 的 asynchronous background process,由於無法自控,故資料在真的被 GC 刪除前還是會出現在 Read Results,所以會需要 filter,而篩選規則可以用:不包括與垃圾回收 policy 相同目標資料,來排除廢棄版本。
總結
每個 Row 可以不用設計完整的 Column,保留很大的擴展彈性
不需要填滿每個 Row 的每個 Column
幾乎可以處理所有類型的資料,因為 BigTable 將其所有資料都視為字串
k-v 模型看起來簡單,卻可以表達成很多形式:
rowkey info:name info:age meta:status 1 小明 19 1 2 小紅 17 0 3 小剛 13 1 像上面的一個常見的表格,在 Bigtable 中其實是如下方式表示:
table1:1:info:name -> 小明 table1:1:info:age -> 19 table1:1:meta:status -> 1 # 上面 3 條記錄共同構成原表中的 Row-Key 為 1 的 row,形成一個 entity最後對於 Bigtable 的一些限制,雖然上面有簡單提過了但還是整理如下:
另外特別注意,Table 屬於整個 Bigtable Instance,而不是屬於任一 Cluster 或 Node,所以其實沒有將 Table 分配給某個指定 Cluster 這種功能,也沒有在不同 Cluster 內的 Table 存不同資料這種事情。
設計範例
Bigtable 論文給出的例子 Webtable 如下圖,需求是想保存大量的 web 和網頁相關的 metadata,這些資料會被不同的專案使用。接下來是對應 Table 設計:
- Row-Key: URL
- contents: 也是 colume family ,存放頁面 html 內容
- anchor: 是 Column-Family ,儲存引用了這個頁面的 anchor(HTML 錨點)的文本
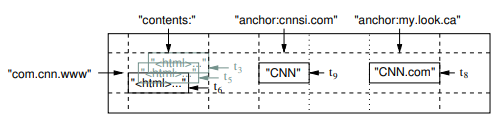
Bigtable 表內部存儲了大量的 web 相關信息如圖中所示,代表 www.cnn.com 被 cnnsi.com 和 my.look.ca 以上兩個給引用了,因此會有 anchor:cnnsi.com 和 anchor:my.look.ca, qualifier 是引用這個網頁的 anchor 名字,而對應的 value 是連結的文本(link text); 另外可以發現 contents column 有三個版本,時間戳分別為 t3, t5, t6 ;
在 Webtable 中,每 row 以反轉的 URL 作為 row-key ,而其對應 value 內容是存儲 web html。會反轉 URL 的原因是為了讓類似名稱的子域名網頁能聚集在一起,可以利用 Locality 提高查詢效率。想要讓 Bigtable 有更好的寫入性能,重點是儘可能均勻平均的寫入不同的 Node 內,故建議 Row-Key 選擇是比較偏向亂序的 ; 同時對有相關的資料進行分組讓他們連續的放在一起。
將多個 column family 組織到一個 locality group,每個 tablet 會為每個 locality group 產生一個單獨的 SSTable。 locality group 詳細研究後是可以增進 Bigtable 很多效能的,可以多多參考
例如 maps.google.com/index.html 頁面在儲存時, Row-Key 就是把字反過來變成 com.google.maps/index.html,其會把來自相同網域的頁面儲存到連續的 Row,會使那些針對「 主機 」和「網域」的分析(host and domain analyses)非常有效率。
Practice
有一個 Cloud IOT application 需要存儲達 10 petabytes(PB) 的資料,且 application 必須支持 high-speed reads and writes pieces of data,好消息是 data schema 比較簡單。承上述需求,最 economical 的 data storage solution,哪個比較合適?
- A. Store the data in Cloud Spanner, and add an in-memory cache for speed.
- B. Store the data in Cloud Storage, and distribute the data through Cloud CDN for speed.
- C. Store the data in Cloud Bigtable, and implement the business logic in the programming language of your choice. (O)
- D. Use BigQuery, and implement the business logic in SQL.
Cloud Storage 和 BigQuery 都不太適合 high-speed Writes 「高頻寫」的場景。Cloud Spanner 是的全球分佈式關係資料庫,它支持強一致性和自動擴展 ; 而 Bigtable 是一個分佈式 NoSQL,也適合處理高頻讀寫操作,並且也可以自動擴展支持大規模 PB 等級的資料存儲。
其實 Cloud Spanner 或 Bigtable 都算可以達成題目都要求,但由於 data schema 很簡單,而且要考量 economical。 Cloud Spanner 通常比 Bigtable 更昂貴,因為其提供更高的強一致性、ACID 事務的功能,且由於 schema 簡單大概也代表應該也沒有需要什麼 table join 之類的,故在這題可能選擇 Bigtable 是比較好的解決方案。
參考資料
[GCP 教學] 043 2 小時學完 GCP 重點服務 VM, LB, Kubernetes, DevOps, 混合雲, 資料庫, 大數據, 機器學習, AI, 網路防禦, 權限, 資訊安全等
Paper Notes: Bigtable – A Distributed Storage System for Structured Data
Essential Cloud Infrastructure: Core Services - Summary Notes - Part 2
[译] [论文] Bigtable: A Distributed Storage System for Structured Data (OSDI 2006)