
GCP - Managed instance groups 概述
Cloud 是最能展現自動伸縮擴展服務好處的平台,而 GCP 的 Autoscaling Groups of Instances 代表產品是 Managed Instance Groups (簡稱 MIGs) ,雖然名稱有一點點不太直覺。 GCP 會根據自訂義的 Autoscaling Policy 來自動添加或刪除 VMs ,這些自動縮放而產生的 VMs 會有一個群組來管體,就是 MIG。對應其他的雲端服務是 :
- Amazon Web Services (AWS) : Auto Scaling groups
- Microsoft Azure : Virtual Machine Scale Set
MIGs 的 Autoscaling Policy 再詳細說一些,是能夠基於 Application 的 CPU/Memory 使用率、網路流量等等設定,自動增加或減少 VM,可根據業務需求或突發流量的場景,靈活調整資源數量從而保證高性能和成本彈性。
在 GCP 中,Instance Groups 是一個用於管理 VM instance 的集合,分成 Managed(受管理的)或 Unmanaged(非受管理的),這兩種類型各有其用途:
Managed Instance Groups
每次 Autoscale 的時候,都會使用 Instance-Template 的設定來創建 VM,這是必要的選項。例如說 Instance-Template 裡面的 Boot-Disk Image 可確定啟動 VM 的 OS 作業系統 ,然後 machine type 可確定 VM 硬體規格等等。
很自然地,若有 MIG 正在使用該 instance-template,則該 instance-template 該雲端資源就無法被刪除
大部份的 VM 設定在先前建立 Instance-Template 時都已經完成了,接下來 Managed Instance Group 基本只要設定 Name 、 Location 以及 Autoscaling 就可以了 :
Location
有分成 Single zone 和 Multiple zones ,若設定成 Multiple zones,則不須擔心當其中一機房掛掉時服務會終止,以實現更高的可用性。
Autoscaling 自動縮放
也稱作 「Autoscaling Policy」 ,可根據 Policy 設定自動增加或減少 VM instance 的數量,還可以設置最小和最大 instance 數量以確保上下限。
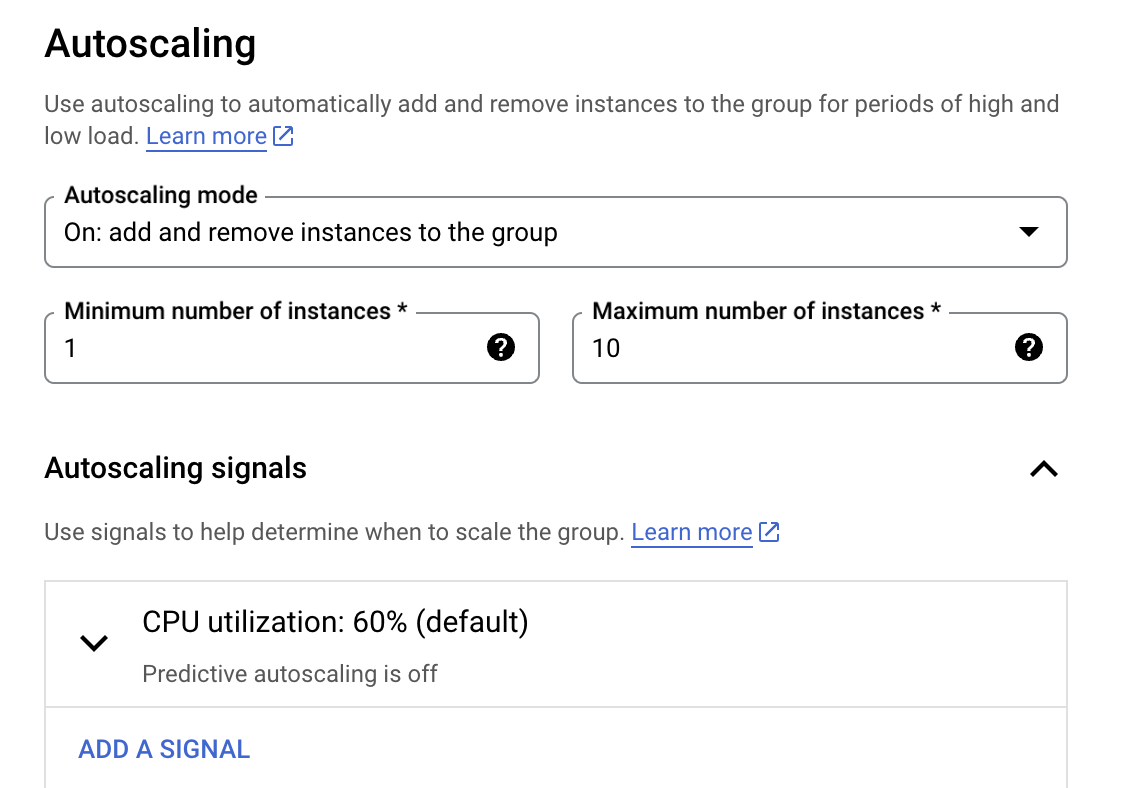
Autoscaling Policy 至少要有定義一個 「Autoscaling signals (縮放信號)」。常用的 signals 指標有:
- CPU utilization - Defult 的
60%CPU utilization - HTTP load balancing utilization
- Cloud Monitoring metrics
- Cloud Pub/Sub queue
還可以進一步設定 Initialization Period(舊稱是 cool-down period),可以設定等待多少時間後,才再根據指標決定 VM 是否繼續增加或銷毀。另外還有 Scale-in Controls 選項讓 VM 數量短時間不要下降太快,實際舉例如在 10 分鐘內降幅不要高於
10%; 或是 5 分鐘內最多不可以關超過 3 台 VMs 。- CPU utilization - Defult 的
Auto Healing 自動修復
主要是會需要 health-check 來偵測 VM 的狀態,而在 health-check 內可以設定等待多久之後才檢查,讓應用程式可以完成初始化。 如果 health-check 發現 VM instance 出現問題,MIG 會自動 Auto Healing 它們,以維持正常運行的 VM 數量,確保應用程序高可用性和其高性能。但注意一下雖然名稱說是 Auto Healing 自動修復,但其實是把不健康的資源砍掉,然後再新建一個資源出來,和我們正常理解的 Healing 是不太一樣的…
這邊注意一下,Load-balancer 的 Backend Service 或者是 Instance Group 本身,都可以設定 health check,但檢查後的行為不太一樣:
- Backend Service : 確保資源健康之後, Load-balancer 才會將流量導向後面的 App
- Instance Group : 檢查若資源不健康,會把不健康的資源砍掉,並重新建立新的資源
使用 MIG 的 Auto Healing 功能,這是自動化維持一定健康數量 VM 來保證服務品質的 Best-Practice
更新策略(Updates strategy)
到目標 Managed Instance Group 內,最上面有 Update VMs 選項,在裡面可以設定新的 Instance-Template,這樣就可以產生新的 VM ,同時可以簡單設定 Updates strategy。 而 MIG 提供 zero downtime 來發布新的 Application 版本,當 Application 有 update 時,通過 rolling updates 逐漸將新 VM 添加到 MIG 中,確保在部署期間 available capacity 不會減少,主要會是設定:
- maxSurge 設置為
1,代表部署過程中會創建「一個」額外的 VM - maxUnavailable 設置為
0,代表確保所有現有 VM 在更新期間保持可用
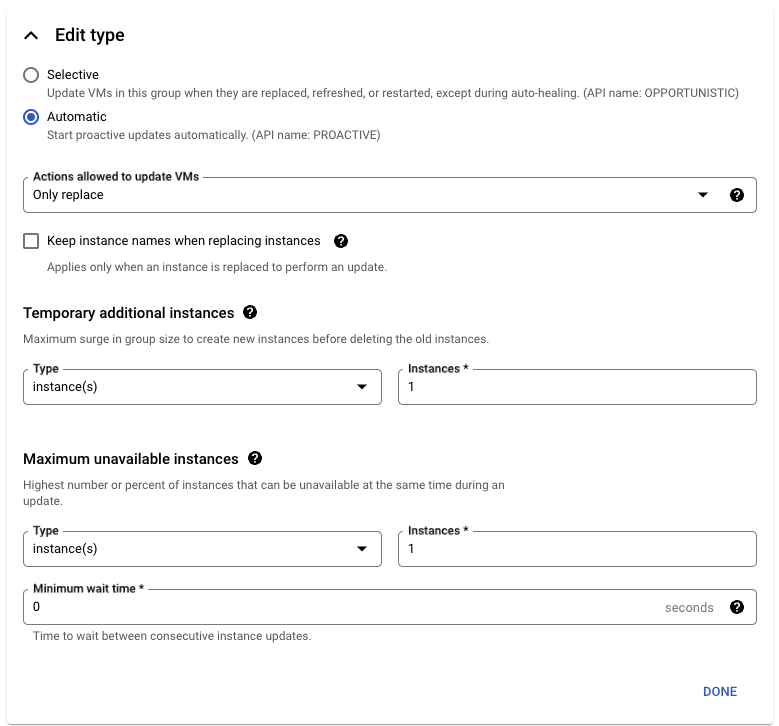
- maxSurge 設置為
Unmanaged Instance Groups
Unmanaged Instance Groups(UIG)不提供自動縮放、自動修復功能。 Unmanaged 的意思其實是 GCP 不控管這個群體的狀態,僅僅只是幫忙劃分個群體類別,並附上和 VPC 和 Port mapping 等網路通訊功能,把狀態管理完全交由使用者。 故 UIG 可以自由地配置不同的 VM instance ,主要用於需要使用現有已經存在的一些 VM。
再次提醒,Unmanaged Instance Groups 不提供自動縮放、自動修復功能
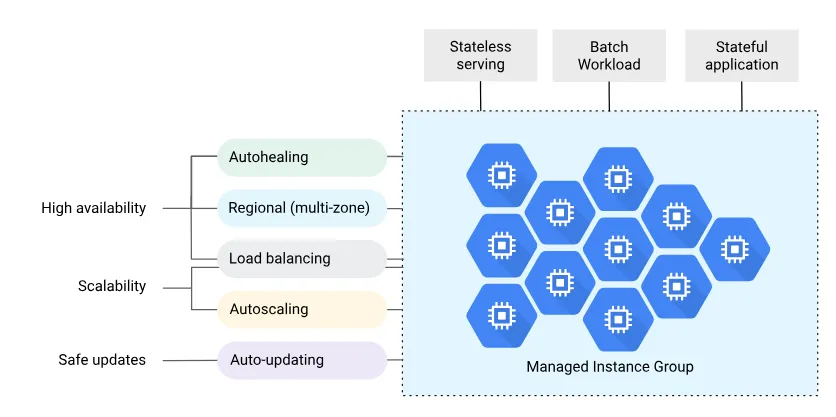
Instance Groups 結合 Load-Balancer
上述說明了兩種類型的 VM instance groups:
- Managed instance groups (MIGs) : 使用 instance-template 建立的 VM,功能有 Auto scaling、 Auto healing 等等,只有 MIG 有 Autoscaling 功能
- Unmanaged instance groups : Unmanaged Instance Groups 沒有提供 Auto scaling 功能,僅只是把一些 VM 資源聚在一起方便管理,可能相關性不大,可能會有不同 machine type、不同 image。
雖然 Unmanaged instance groups 看起來有點沒作用,但是還是把這一些不能隨意 auto-scale 的 instances 聚在一起成一個 Instance Group ,其中一個很大的原因是藉由一個抽象化 Instance-Group Interface ,就可設計與 GCP Load-Balancer 結合使用。
Load-Balancer 能控制流量使之分流到某些「目標」 ,其會使用到的抽象介面可以想成是 Instance-Group Interface,有了這個 Instance-Group Interface 後,個別 group 實現類如 MIG、UMIG,甚至更特別的 NEG, Load-Balancer 都可以簡單透過 Interface 來分配流量了。
Practice
有一個 Mig 且有開啟 autoscaling 功能且 Mig 內已經有管理多個 VM ,現在有 App 應用執行在 VM 上,然後 autoscaling policy 有設定:
- 當 CPU utilization 超過
80%時,會向 Mig 中加更多 VM- VM 最大上限
5個 ; 當 CPU utilization 降至80%以下就不在添加 VM- HTTP health check 的 initial delay 設置為
30s已知 VM 啟動完成,需要大約
180s才能對 user 可用。當 Mig 自動擴展時經常發現會過度添加 VM ,那應該怎麼做才能避免這種情形?
由於 VM 需要 180s 才能對 user 可用,一開始設定的 health check 的 initial delay 才 30s,會造成健康檢查過早而失敗,才觸發了不必要的 autoscal。故可能可以考慮把 將 HTTP health check 的 initial delay 增加到 200s(> 180s),可讓 VM 有足夠的時間來完全啟動好,從而防止不必要的 VM 自動擴展。