
GCP - Cloud Spanner 概述
Cloud Spanner 是 Google 開發的一個完全託管關係型資料庫,屬於企業級 PaaS 解決方案,具有全球同步、全域事務、強一致性、可擴展、分散式和 Replica/Failover 功能,可保證
99.999%可用性 SLA,使用者不需要多花心思在底層的基礎建設與管理。對應其他的雲端服務是 :
- Amazon Web Services (AWS) : Amazon Aurora
- Microsoft Azure : Azure SQL Database (SQL Server base)
Cloud Spanner 於
2012年開始為 Google 內部的重量級產品如 Youtube、Gmail、Google PlayStore 等等提供服務,取代了 Google 的自定義 MySQL 且號稱是盡量滿足 CAP 理論限制。2020Q1 統計每月約 1 億活躍使用者,每天有高達 1800 萬次外送記錄的 Uber,是使用 CLOUD SPANNER 成功案例。
Cloud Spanner 有 Free Trial 可讓人免費試用 90 天並提供 10GB 儲存空間,可以隨時升級到付費版本,以繼續使用並解鎖全部功能,例如 Scale Out 和 Multi-Region。
Cloud Spanner 的 Free Trial 模式,如果 90 天試用期後還是沒有升級成付費模式,則 Cloud Spanner 將停止處理請求並進入 30 天的寬限期。在寬限期內資料會保留,如果在 30 天寬限期結束前也未升級成付費版,則資料就會會被完全刪除。
Cloud Spanner Architecture
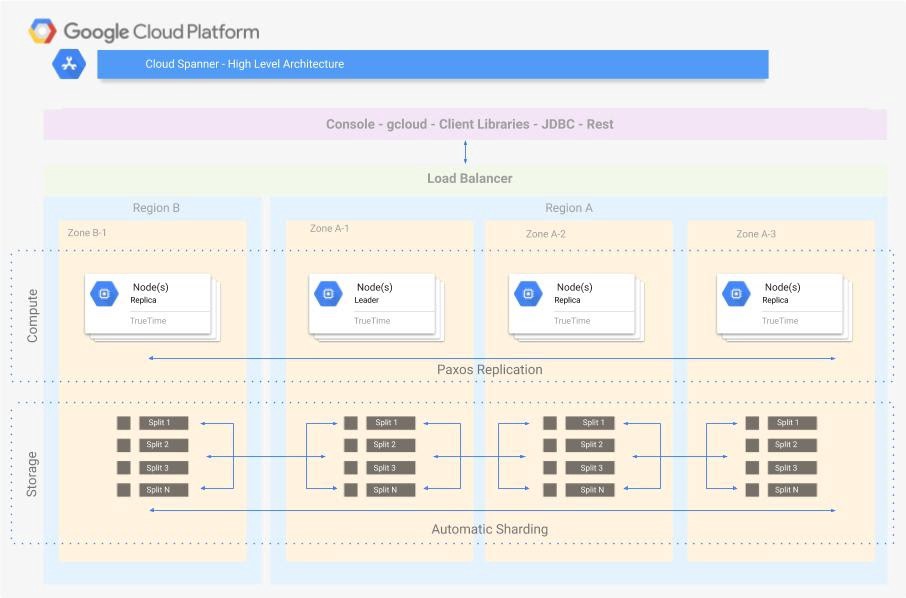
要在 Cloud Spanner 中創建資料庫,首先需要創建一個 Instance ,並設定該 Instance 中的資料庫要使用的「 Replication Topology 」 、「 Compute Resources 」,首先做一些名詞介紹:
- Replication: 資料的副本類型
- Topology: Replica 資料的存放地理位置類型
- Compute Resources: 定義計算能力的資源
對於任何區域配置,Cloud Spanner 都會維護多個 Replicas, 每個 Replicas 會位於該 Region 內不同 zone 中,並基於 Paxos 分散式共識協議,會跨所有 Region/Zone 同步複製並會對寫入請求做投票,然後執行仲裁(quorum) 確認後,會才 Commit Transaction ,然後持續且穩定地複製跨大區域間的資料,就算有資料中心突然發生問題,也能存取 Replica 來達成強一致性和高可用性。
Replication
Cloud Spanner 將 Table 內的資料根據 Primary-Key 的範圍,切分成多個 Splits,每個 Split 都有多個備份稱為 Replicas。
Split 比較屬於強調 Cloud Spanner 會將 Table 內的資料分散的能力 ; 由於 Split 都一定會有多個 Replicas 備份,加上既然是備份資料,那概念上其實 Split 和 Replica 沒有任何區別,故也常直接把 Split 就稱為 Replica 了。
Replica 有不同的類型分別是:「Read-Write」、「Read-Only 」、「Witness」,其特色可參考表格:
| Replica Type | Can Vote | Can Become Leader | Can Serve Reads | Can Configure Replica Manually |
|---|---|---|---|---|
| Read-write | yes | yes | yes | no |
| Read-only | no | no | yes | yes |
| Witness | yes | no | no | no |
其中有一些值得關注的點:
- 從表格中可知道只有 Read-write 有機會成為 Leader
- 從表格中可知道 Witness 主要只是用來幫助投票而已
- Read-write 和 Read-only 有完整的資料,但 Witness 並沒有完整資料
因為要做到非常高的可用性,所以 Cloud Spanner 一次就會產生至少 3 個 Replicas 都放在不同 Region,承前也有提到會直接把 Split 就稱為 Replica,再繼續思考 Split 的由來是 Table ,而 DB 資料由多個 Tables 組成,故把 Cloud Spanner 當成會冗余至少 3 個 DB 概念上也行,以下圖片都是以這樣的概念呈現:
Witness Replica
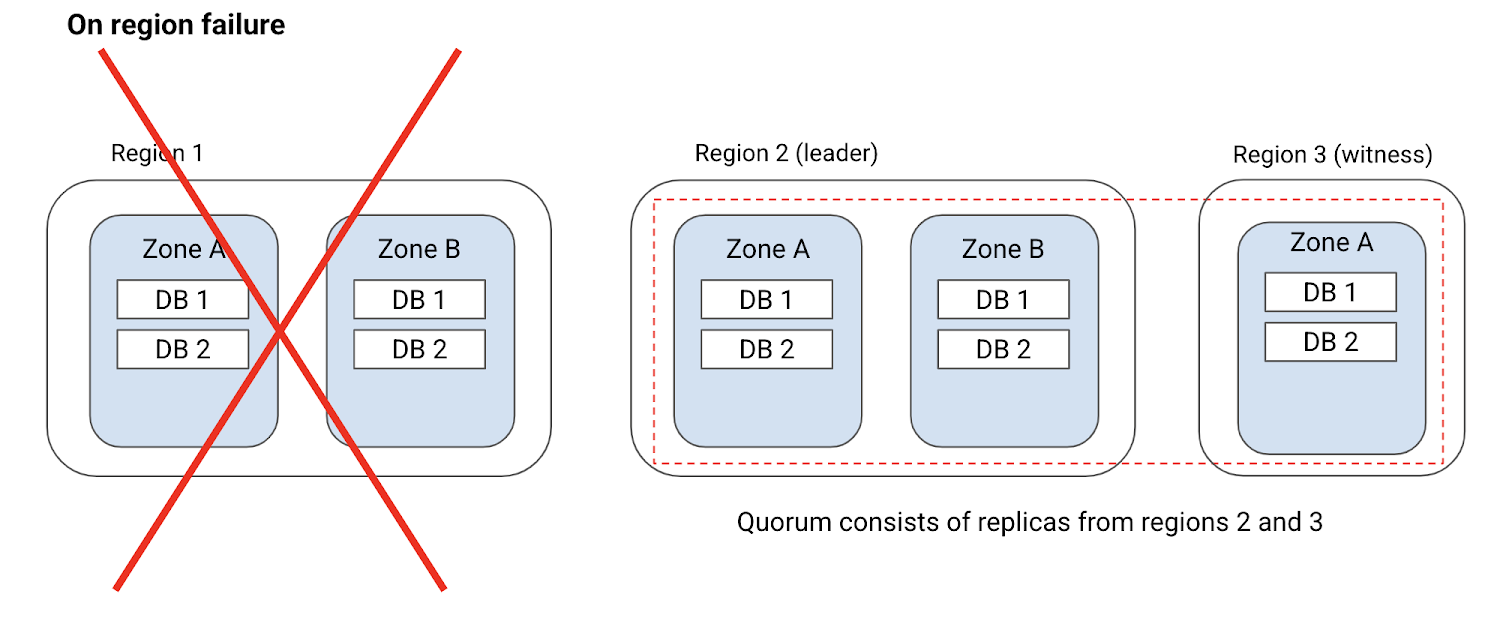
為什麼需要「Witness Replicas」是因為要考慮面對 Region-Failure 層級故障仍然要保證 Available 可用性。因為如果只在兩個 Region 中有 replica 但沒有再加第三個 Region 的 witness ,則在任一 Region 發生問題後,就無法完成多數 vote 仲裁。
參考下圖,是因為有了另一個 Region 的 Witness,所以就算任何一個 Region 故障,對於任何一個 Replica 還是有 3/5 > 50% 存活著可以投票, quorum 仲裁還是可以運作。
Read-write replicas 中選擇一個成為 Leader Replica
為了確保強一致性, Cloud Spanner 會使用基於 Paxos 同步複製的算法從 Read-Write Replicas 中選擇其中一個成為 Leader-Replica 簡稱 Leader。所有 write-request 會首先發送到 Leader ,它負責處理寫入操作和轉發,再來 Leader 會發送 Write 給其他 Replicas ,只要其他 Replica 完成 Write 後,就會回覆給 Leader 並 voting 。
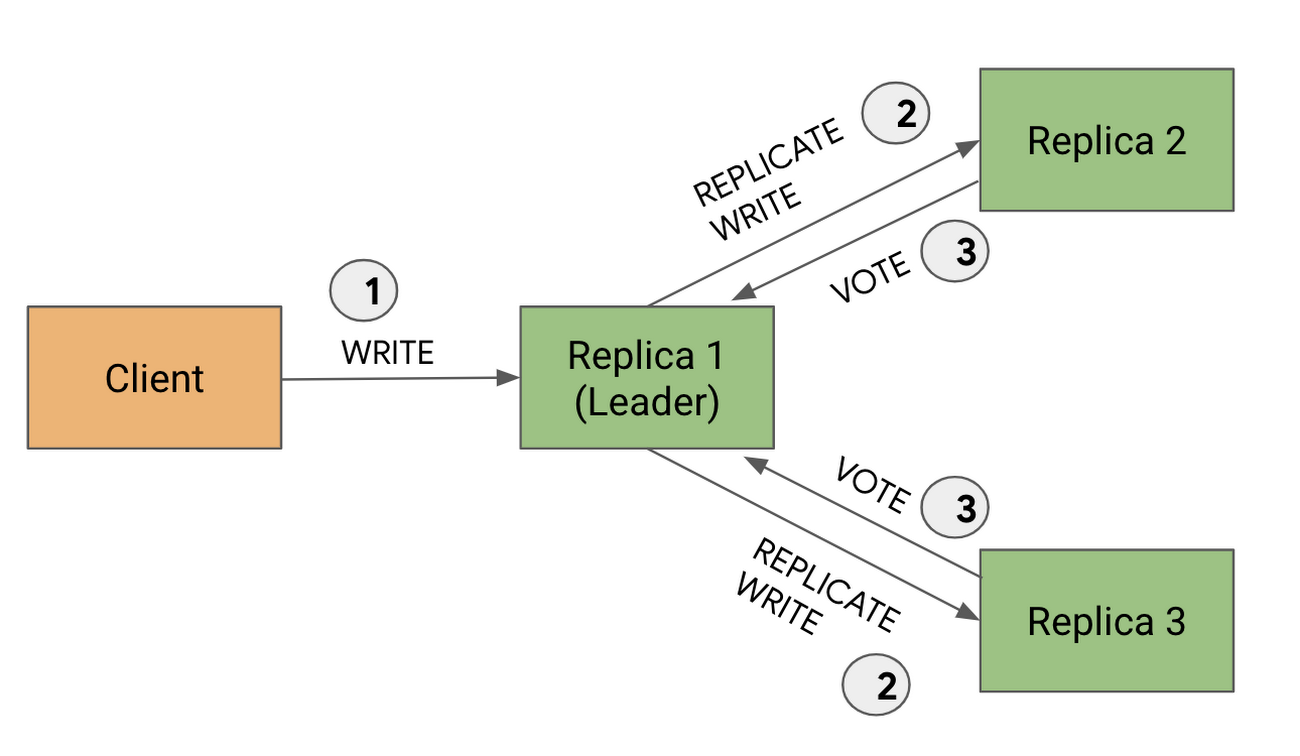
當若大多數 Replica(總稱為仲裁 quorum)都投票是 commit Write,則 Leader 就認為已經 committed Write 。如果這時其他 「read-write replica」或「read-only replica」發現自己 commit 落後的話,就會從其他有完整的 replica 把資料 copy 過來到自己身上。
Leader 自己本身也會參與 vote,只是還多個功能是通知其他 replica write
Replication Topology
創建 Cloud Spanner 時,首先 GCP Console 上會先定義 Replication 要在哪個地理位置,有 Regional 、 Dual-Region 、 Multi-Region 可以選擇。另外在前面的 Replication 章節有提到常直接把 Split 稱為 Replica ,再往前一步推理我們也知道 split 是 Table 的部分資料,再加上 Table 是屬於資料庫的,所以可以等同於 Cloud Spanner 是把 DB 同步複製備份到多個地方,因此也可以說 Split 等效於一個 DB,故下面圖中就以此為概念表示。
Single Regional
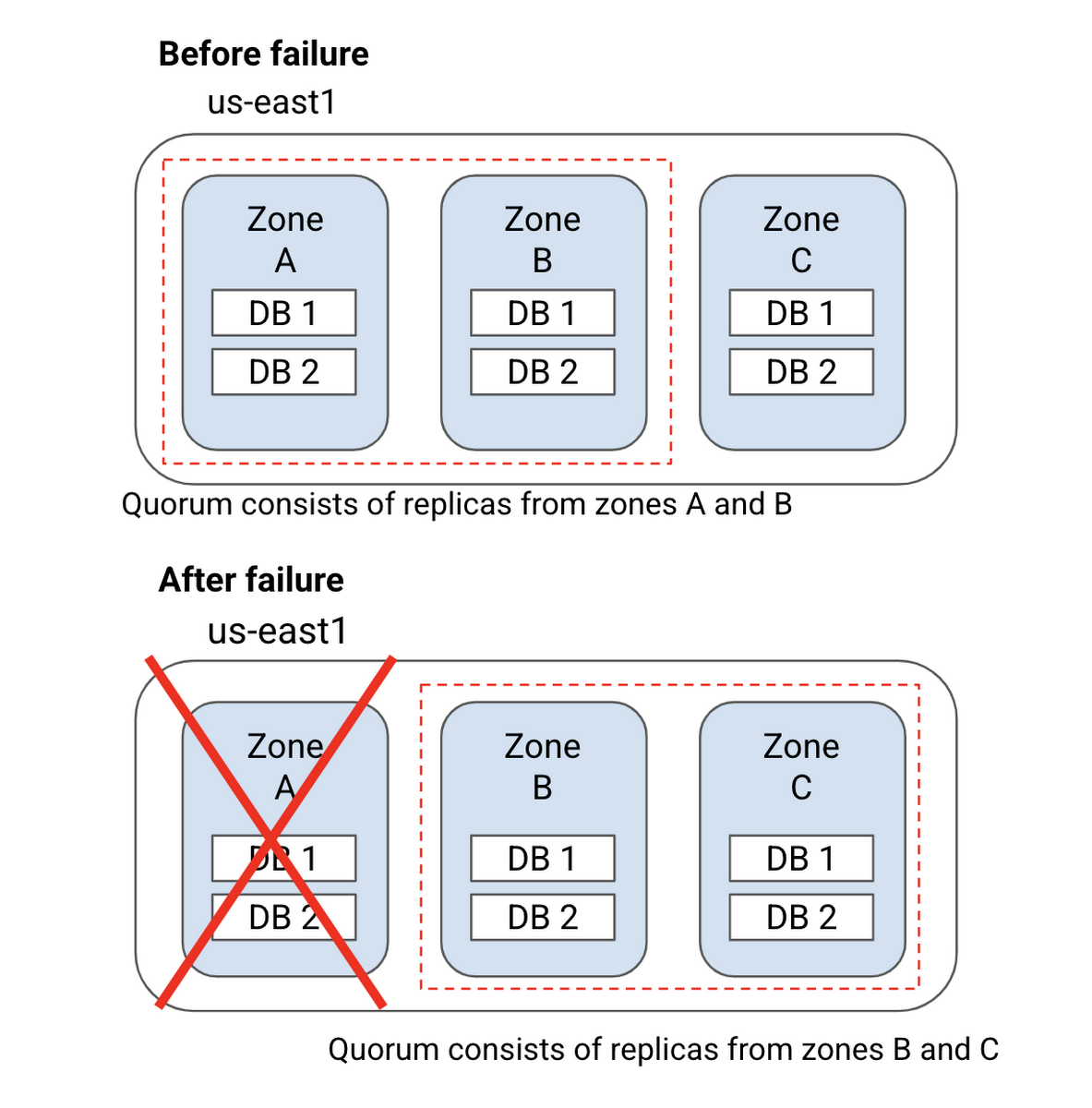
- Regional: 所有資源都留在單個 Google Cloud Region 內。有 3 個 Read-Write Replicas 都分散在不同 Zone
對於 Regional ,由於 Replicas 都會位於不同 Zone 中 且有 3 個 Replica ,若發生 Single-Zone Failure 的話還是有 2 個 Replica 可用,還是可以形成 2/3 >= 50% 的投票率,故可以仍然保持 Available 可用性。
Multi Regional
Multi Regional 有兩種,Dual-Region 和 Multi-Region 都算:
- Dual-Region:資源會跨度兩個 Region ,但基本還是位於一個國家內,例如 dual-region-japan1 代表
Osaka/Tokyo。每個 Region 都有 2 個 Read-Write Replicas 和 1 個 Witness Replica
- Multi-Region:資源跨越多個區域。如果想要將 App 擴展到新的地理位置或者使用者遍佈全球,並且希望通過在 User 地理位置附近放置 Replica 來減少讀取延遲,那麼這是一個不錯的選擇
從文件中發現 Read-Only Replicas 只有在 Multi-Region 才可能會有,主要是讓讀取速度加快,故 Multi-Region 的 Replicas 配置比較多樣,例如說:
nam3:- 在
us-east4和us-east1區域中各有 2 個 「Read-Write Replicas」 - 在
us-central1區域中有 1 個 「Witness Replica」
- 在
但是
nam6:- 在
us-central1和us-east1區域中各有 2 個 「Read-Write Replicas」 - 在
us-central2區域中有 1 個 「Witness Replica」 - 在
us-east1和us-east2區域中各有 1 個 「Read-Only Replicas」
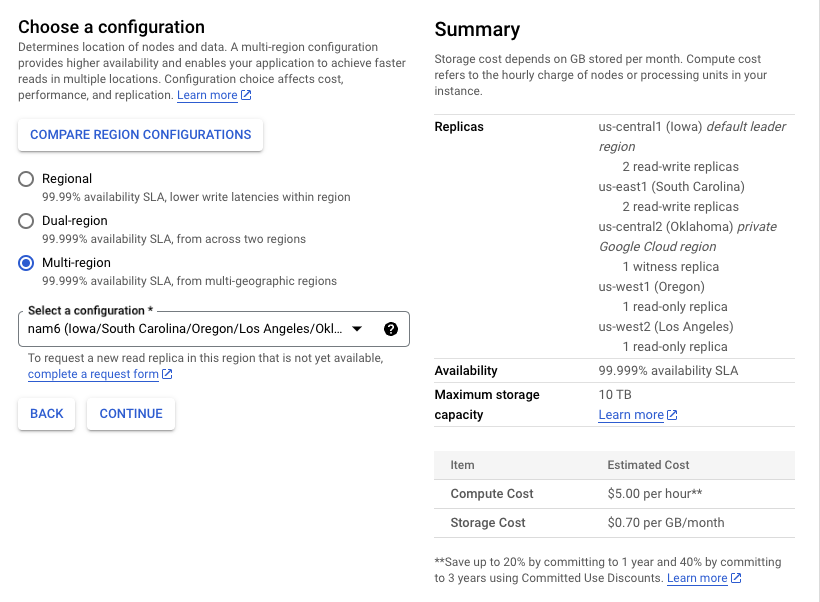
- 在
Cloud Spanner 現在可以在建立完 Instance 後更改 Replication Topology,也就是可以從 Regional 變成 Dual-Region 或 Multi-Region 的,移動實例不會導致停機,並且移動過程中也會盡量保證 Transaction 的 strong consistency,但是會有高 CPU 使用率、雙倍付費等等問題,需謹慎規劃。
Cloud SQL 的 scalability 只能在單一 Region level ; 如果需要 RDB 能跨越 Region level 的 scability 就可以考慮使用 Cloud Spanner
Compute Resources
Cloud Spanner 在創建 Instance 時有 Compute Capacity 的設定,這是用來控制「 性能 」和 「 容量 」的。Compute Capacity 設定的單位可以選擇 Node 或者 Processing Units (PUs) 來表示資源能力(只能選擇其中一個):

100 PUs = 1TB。注意 Cloud Spanner 中的 Node 與 Replica 是不同的東西:
- Node 表示可供 Cloud Spanner Instance 使用的 Compute 和 Storage 的資源量
- 例如
1-node regional instance和一個2-node regional instance都一樣是有 3 個 Read-Write Replicas 都分散在不同 Zone - 但不同之處在於
2-node regional instance的 Compute 和 Storage 資源量是1-node regional instance的兩倍。
在 Cloud Spanner 要擴展資料庫的容量或運算能力話,只需要提升更多 Node/PUs 就可以了,添加 Node/PUs 不會更改 replica 數量,但會添加更多的 Compute(CPU 和 RAM)和 Storage 資源,從而提高 App 的 throughput。
Cloud Spanner 總結
Cloud Spanner 專門設計用於在不犧牲一致性的情況下,可跨多個區域水平擴展。可處理的資料量非常大且處理資料的速度也很快,並可同時保持 Transaction 一致性。
可擴展性
傳統的 RDB 的水平擴展和跨大區域的資料複製會困難些,需要考慮分片(Sharding)或叢集(Clustering)設定。 而 Cloud Spanner 提供很簡單且強力的水平延伸性和分散式能力,通過自動分佈資料和自動處理複製,只需簡單調用 API,就可以從小型工作負載開始簡單的擴展,無需重寫應用或 Migration DB。
Cloud Spanner 對 PostgreSQL 的支援度會比較高,從 PostgreSQL 轉到 Spanner 也會比較方便
一致性
傳統的 RDB 經常最終只能達到 Eventual-Consistency 終將一致性,故還是可能會有提供到舊資料的風險,這在像金融業和遊戲業某些專案下,可能是不可接受的。而 Cloud Spanner 使用 True Time 技術依靠原子時鐘和 GPS 來獲得全球 Node 之間的時間同步,而可以確保 DB 在不同 Node 上的時間戳記是可靠的,並會為每個 Transaction 打上時間戳,確保不同區域的事務可以順序執行。
高可用性
傳統的 RDB 通常依靠手動複製和故障轉移機制來實現高可用性。而 Cloud Spanner 支持全球的自動複製和資料冗餘,在獨立 region 之間進行同步複製,可以保證系統在任何單點失效或者還是整個區域故障的情況下仍然可用,提供 99.999% 的服務層級協定(Service Level Agreement,SLA)來展現高可用性。