
GCP - Cloud SQL 概述
Cloud SQL 是 GCP 提供針對 MySQL、PostgreSQL、SQL Server 推出的完全託管關係型資料庫服務,讓使用者能夠從資料庫的管理任務中解放出來,花更多時間在資料本身而非硬體維護。雲端資料庫只是在雲端上建置、部署和存取的資料庫而已,其底層操作和傳統地端資料庫完全一樣,對應其他的雲端服務是 :
- Amazon Web Services (AWS) : Amazon RDS
- Microsoft Azure : Azure SQL Database for MySQL/PostgreSQL
Cloud SQL 除了可快速啟用資料庫,還可以同時整合讀寫分離、同步、自動備份、監控等等,也讓我們能更安全便捷地整合 GCP 的其它雲端產品例如:「創建 Table 並從 Cloud Storage 導入 .sql 資料」、「使用 Cloud SQL Auth Proxy 連結到 Compute Engine」、「連接到 BigQuery 來使用聯合查詢」等等。
Cloud SQL Instance
每個 Cloud SQL Instance 都運行在 GCP 託管的環境內,其環境我們並不可控,每個環境都運行著 Database-Program 和其 Service-Agent(例如 Logging 和 Monitoring)。 若有啟動 High-Availability 選項則還會在另一個 Zone 中提供備用環境,配置都相同。
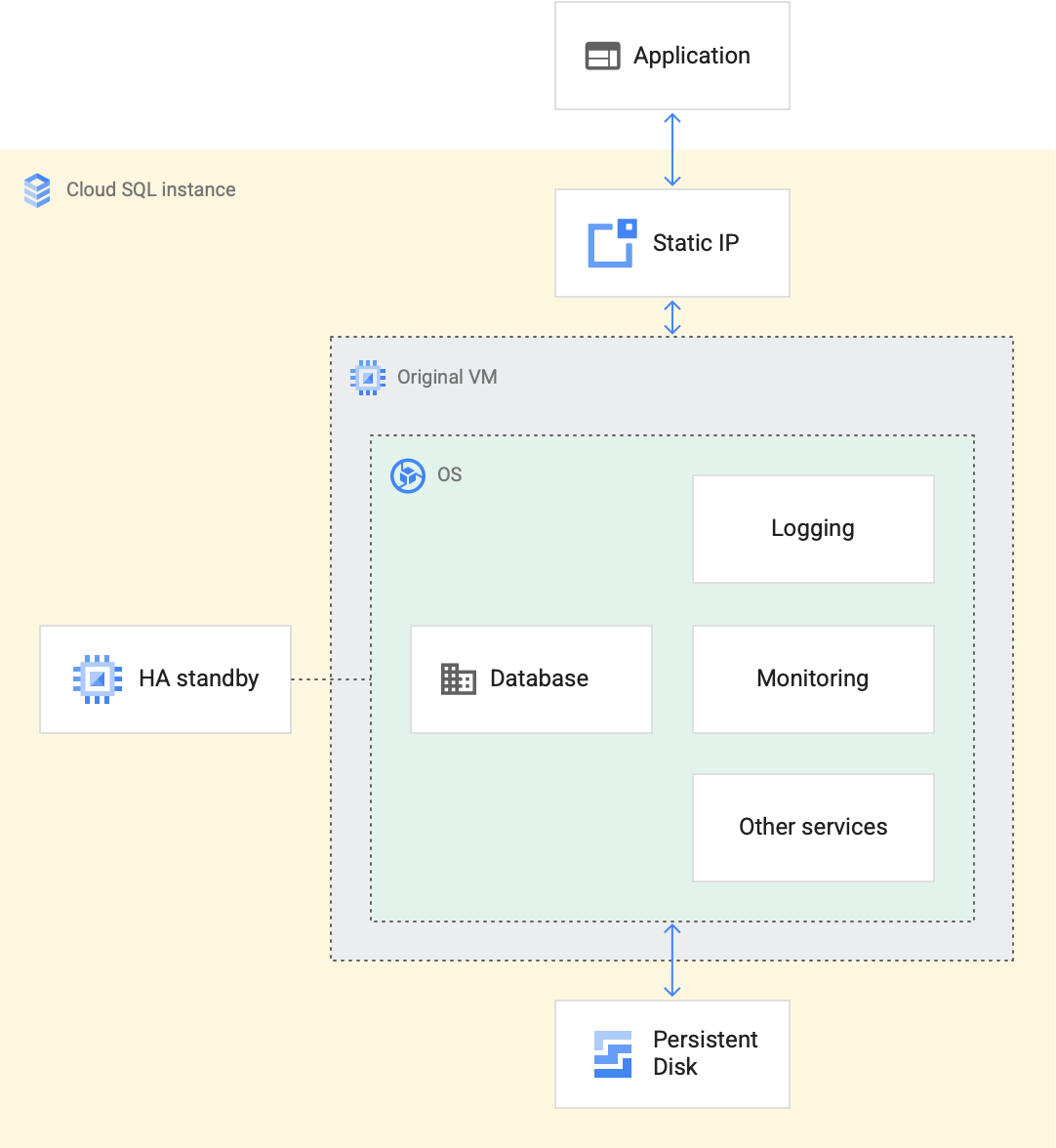
Persistent Disk 附加在 SQL Instance 上提供資料庫 Scalable 和 Durable。而 Cloud SQL 的自動擴充是指儲存空間的自動擴充,並「 不是 」自動增加硬體的 CPU 跟 Memory,對於 CPU 跟 Memory 是需要人工手動去調整的
Static-IP-Address 位於每個 SQL Instance 的前面,以確保應用程式連接到的 IP 在 Cloud SQL 的整個生命週期內都存在
上圖中雖然看到 VM 這個關鍵字,但這個 VM 並不是我們在 compute engine 上開的機器,是 GCP 專門為 SQL 相關軟體運行所提供的環境,我們是無法查看到關於該環境的全部底層訊息的
Cloud SQL 提供的功能
High Availability(HA)
在剛開始建立 Cloud SQL 時就需要設定是否開啟 HA 即 Multi-Zones ,可以把開啟 HA 服務的 Cloud SQL Instance 稱為一個 Regional Instance,其 Instance 的建立是按照 Zone 去部署的,而 HA 的實踐便是在不同的 Zone 進行 Standby Instance 的部署,並搭配 Regional Persistent Disk 達到資料的跨 Zone 同步寫入。
注意 Multi-Zones 是一種高可用性設置,不是解決 DB 性能問題的,故它不會直接改善 DB 的負載
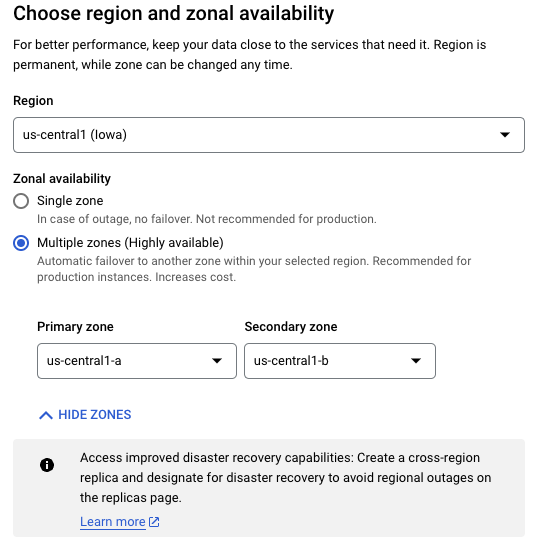
當 Primary Instance 所在的 Zone 的機房發生異常或是主機本身出現異常如記憶體不足時,Regional Persistent Disk 便會掛載至 Standby Instance 來提供服務。
雖然 HA 提供了強大的備援能力,但相對的也需要為此支付額外的設置費用,需審慎評估自身需求選擇是否開啟 HA
Data Protection
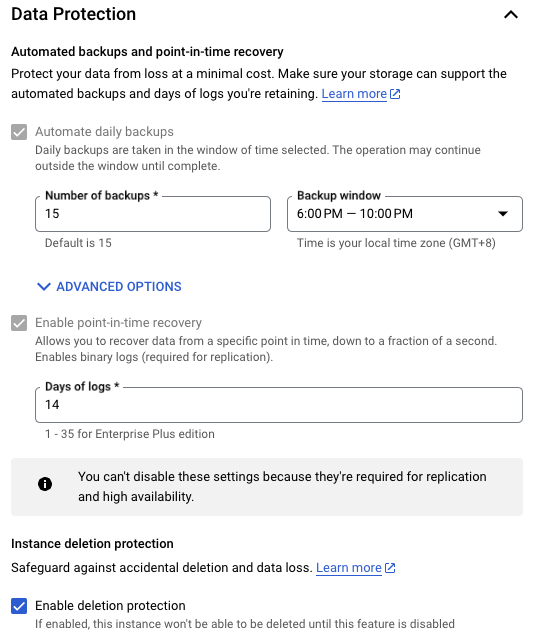
在剛開始建立 Cloud SQL 時有一個 Data Protection 設定,這個就是關於 Backups 和 Point-in-time Recovery 的設定 :
Point-In-Time Recovery (PITR)
PITR 其實就是透過 Binlog 這個紀錄資料庫 Transaction 操作細節的二進制 Log,來達成倒回資料庫狀態至特定時間點。一般是在系統發生錯誤導致資料遺失時,用來恢復資料庫至錯誤發生前的狀態,減少因錯誤產生的資料缺失成本。
Cloud SQL Instance 創建時,預設就會開啟這項服務。而開啟 Point-in-time Recovery 也代表會收集額外的 Binlog 產生額外的儲存成本,操作時需特別注意 Binlog 的儲存時效設定
Backups
關於備份在 Cloud SQL 上提供了 On-demand 與 Automated 兩種備份機制 :
On-demand提供隨時的手動備份,該備份不會被自動刪除,可長時間保存,通常建議在要做一些對資料庫有影響的操作前,執行 On-demand 這項功能來保護資料Automated則是透過設定執行備份的 Backup Window,指定要於哪個時間內執行自動備份。該備份預設保存 7 天,但保留時間可透過修改設定來指定,一般會建議 Backup Window 的設定時段應選在資料庫操作頻率最低的時間段執行,避免影響效能
Replica
建立 Cloud SQL 建立完成之後,可以去 Primary Instance 內設定 Replica,但在建立主 primary instance 的 Replica 之前有一些前置條件:
- 必須先啟用 backups
- 必須先啟用 PITR
- 至少先創建一個 backup
關於 Cloud SQL 的 Replication 有蠻多種類的如「 Read replicas 」、 「 Cross-region read replicas 」、 「 Cascading read replicas 」、 「 External read replicas 」等等,其中先介紹比較常用的兩個:
Read Replica
Read Replica 基本上是精確複製 Primary-Instance 上的資料,但它不能 Write 寫資料,只會針對讀取資料庫的請求專門處理,減少對 Primary-Instance 的負荷,增加服務效能,標準的讀寫分離應用
Cross-Region Read Replica
上面有提到簡單的 Read Replica ,但特別注意單純 Read replicas 不提供 failover capability,並沒有故障故障轉移功能,而「 Cross-Region Read Replica 」能進一步規劃備援或異地備份方案,能在 Primary-Instance 異常事件發生時,快速將其 Replica 轉為新的 Primary-Instance
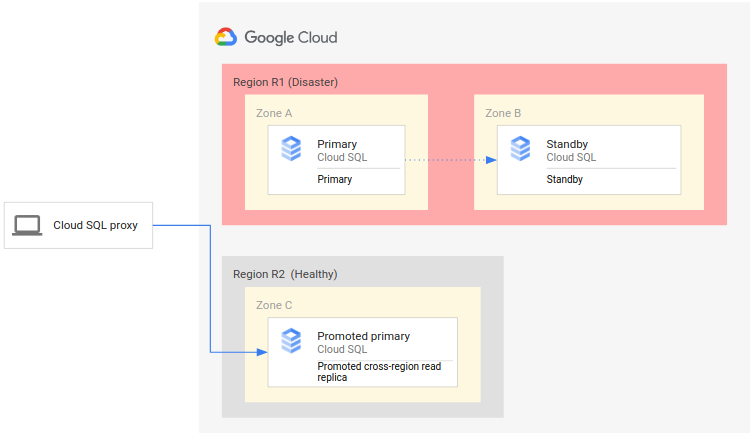
Read Replica 專門用來處理讀取請求,可以將讀密集型的操作(如實時分析)轉移到只讀副本,從而減少主 DB 的負載,這是一個有效改善 response 變慢的解決方案。
Cloud SQL 的連線
Cloud SQL 開起來之後,因為它概念上並不是給一個裝了 DB 的主機讓你操控,故沒有 SSH 連進去的功能,我們沒有辦法直接進入到它的 VM 底層。在考慮如何連接到 Cloud SQL Instance 時有很多方式和其優缺點:
是否讓 DB 可以從 public internet 連線,還是只要使用 private VPC
- Internal: VPC-only (Private) IP address
- External: 外網可存取 Internet-accessible (Public) IP address
Cloud SQL Instance 可以同時具有 External 和 Internal 位址。
是打算寫自己的 connection code,還是使用例如其他連接工具
Database connections 都會消耗資源,故如需自己寫程式來連線 DB 都要注意連線管理,減少超過 Cloud SQL 連接限制的可能。還可以使用以下工具 :
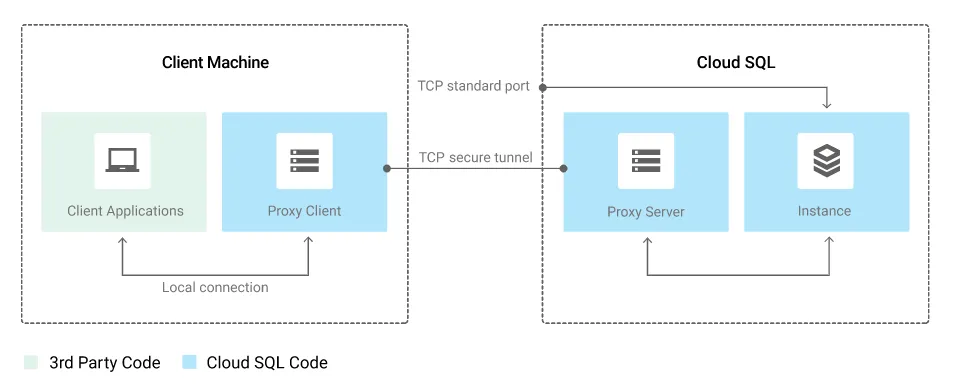
- Cloud SQL Auth Proxy
- Database administration 等 DB Client 端產品,比如說常見的產品有
MySQL Workbench、SQL Server SSMS等等,可以來觀看 DB 資訊。
目前很不錯解決方案是使用「Cloud SQL Auth Proxy」進行連線,此解決方案提供 IAM permissions 使用 Service-Account 的 Credential 來連線,Cloud-SQL-Auth-Proxy 也是 GCP 官方提供且推薦的認證連線方式。
Authenticate
單純 Granting-Access 給 application 並不會自動啟用 User-Account 使之可以連線 DB ,還是需要 configure default user account :
- Built-in database authentication 使用
username/password - 是否要求 SSL/TLS 進行加密,或者允許未加密連線
- Built-in database authentication 使用
Practice
被一家 oil company 聘請負責將 Oracle DB 和 DB2 遷移到 Google Cloud。以下哪個是最佳選擇?
- A. CloudSQL for Oracle and VM for DB2
- B. CloudSQL for both Oracle and DB2
- C. VM for both Oracle and DB2
- D. Google App Engine for both Oracle and DB2
Cloud SQL 目前「只支持 MySQL、PostgreSQL 和 SQL Server」,還不支持 Oracle 或 DB2,因此無法將這些 DB 直接遷移到 Cloud SQL,故 A.B. 都是錯的,因此只能選擇在 Google Cloud 的 VM 上來運行 Oracle 和 DB2,可以完全控制 DB 的配置和管理,故選 C.
Google App Engine 是一個 PaaS ,專為 APP 開發和部署而設計,並不適合運行 DB ,它更多是為 APP 提供自動擴展和運行環境。