Fluent Bit 基礎介紹
Fluent Bit 是一款使用 C 語言編寫的開源的資料收集器,為 Fluentd 的輕量化版本,也是 Cloud Native Computing Foundation(雲原生運算基金會) 下的一個子項目。可以從多種不同來源【如 Log file、kafka 等等】,收集 Logs、Metrics、 Traces 資料,然後輸出至多種不同的服務 【如 Loki、Fluentd、Elasticsearch、DataDog、Kafka 以及各式雲端服務】。

前言
Fluent Bit 設計的最初目的是為了收集 IoT 設備的 Log,這些設備大多使用 Embedded Linux 且硬體資源很少,因此資料收集器必須要盡可能的輕量化,使其能夠在資源有限的設備上運行,也經常用在 Kubernetes 環境中。 fluent-bit 目標是收集、解析、過濾、最終把資料發到目標位置儲存。以下介紹一些術語 :
Event or Record
可以簡化地認為 Fluent Bit 將收到的 Log 中的【一個 row entry】 ,轉成 【一個 Event】 或稱 【一個 Record】。我個人習慣稱為 Record,舉例來說 Syslog:
Jan 18 12:52:16 flb systemd[2222]: Starting GNOME Terminal Server
Jan 18 12:52:16 flb dbus-daemon[2243]:這 4 條 row entry ,會變成 4 個 Record 。 Record 的格式為:
[[TIMESTAMP, METADATA], MESSAGE]
- TIMESTAMP:時間戳記
- METADATA:從 2.1.0 版開始新增的資料,以 key/value 形式儲存
- MESSAGE:資料內容
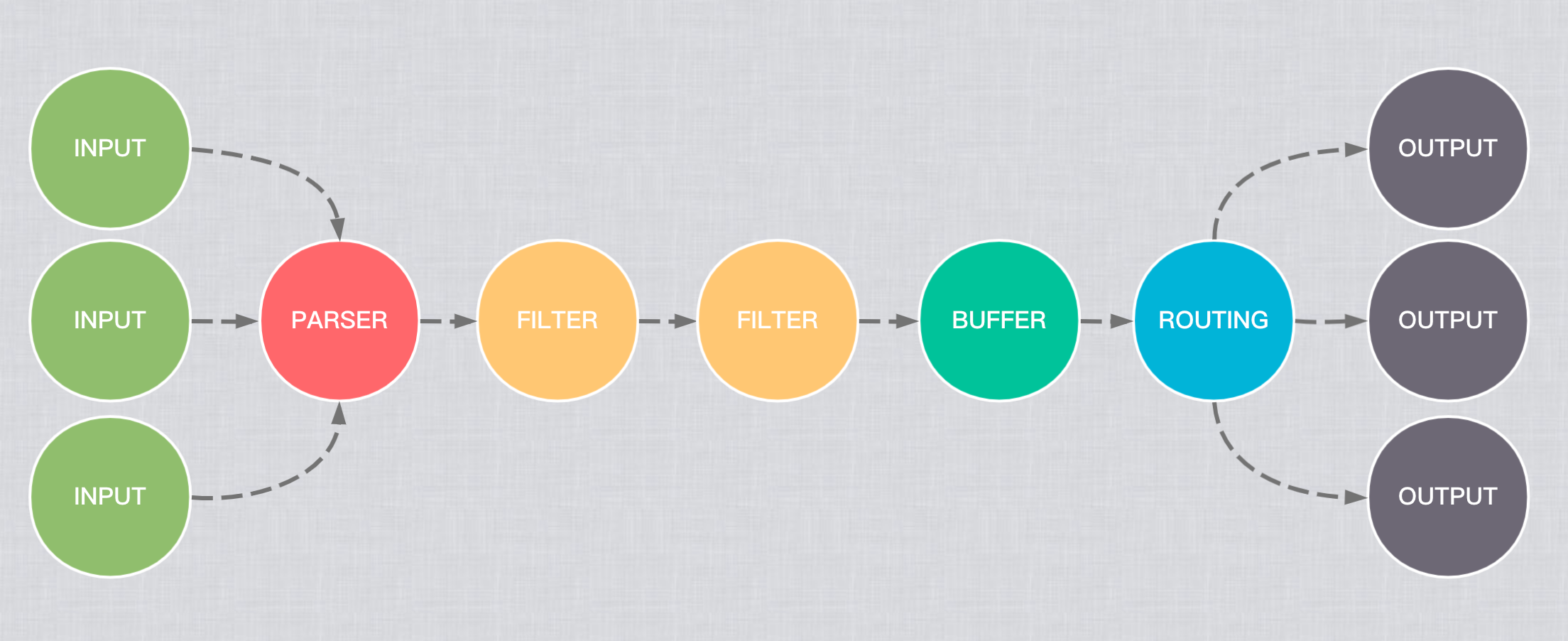
Pipeline
Input
資料的來源。fluent-bit 提供了各種各樣的 Input plugin ,例如可以從 Log File 讀取每一個 row entry、從作業系統收集一些 metrics 等等。
一個 Pipeline 中可以包含多個 Input。
Parser
將資料轉換為結構化資料以便後續處理。通常情況下,我們期望在收集到 Input 資料後,可以馬上轉換為結構化的資料,預設可以處理Apche、Nginx、Docker 等 Log 了;對於不規則的 Log 也可以透過 Regular Exp 來擷取所需部分。
每個 Input 都可以定義自己的 Parser(可選)。
Filter
雖然名稱是 Filter ,但是其實可以對 Record 進行 filter 、 add field 、 delete field,等等修改操作。支援使用多個 filter 一起使用,常用的 filter plugin 包括 Grep、Lua、Modify 等等。
一個 Pipeline 中可以包含多個 Filter,其執行順序與設定檔中的順序一致。
Buffer
是一種緩存機制。當 Output 無法連線或是暫時無法處理資料時,會先將資料暫存起來,待 Output 可以處理時再送出,以避免導致資料的遺失。Buffer 的配置是在:
- Service
- Input
緩存 data 不是原始 data,而是 Fluent Bit 的內部二進位表示形式。
Routing & Output
從 Filter 拿到的 Record 後,可以傳送到一個或多個目的地。規則是
- Input 的 Tag
- Output 的 Match
由以上兩個對應詞的連接,決定 Record 要送往哪個 Output 。而Output 代表資料的目的地,可以是輸出成另一個 file、elasticsearch、Loki 等。